
Author:glls
Version:9.0.1
[TOC]
一、引言
1.1 海量数据
在海量数据中执行搜索功能时,如果使用MySQL,效率太低。
TODO mysql 索引相关的面试题???
1.2 全文检索
在海量数据中执行搜索功能时,如果使用MySQL,效率太低。
1.3 高亮显示
将搜索关键字,以红色的字体展示。
二、ES概述
2.1 ES的介绍
ES是一个使用Java语言并且基于Lucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于RESTful风格的WEB接口,官方客户端也对多种语言都提供了相应的API。
Lucene:Lucene本身就是一个搜索引擎的底层。
分布式:ES主要是为了突出他的横向扩展能力。
全文检索:将一段词语进行分词,并且将分出的单个词语统一的放到一个分词库中,在搜索时,根据关键字去分词库中检索,找到匹配的内容。(倒排索引)
RESTful风格的WEB接口:操作ES很简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数的同,执行相应的功能。
应用广泛:Github.com,WIKI,Gold Man用ES每天维护将近10TB的数据。
2.2 ES的由来
| ES回忆时光 |
|---|
 |
2.3 ES和Solr
- Solr在查询死数据时,速度相对ES更快一些。但是数据如果是实时改变的,Solr的查询速度会降低很多,ES的查询的效率基本没有变化。
- Solr搭建基于需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入。
- 最开始Solr的社区可以说是非常火爆,针对国内的文档并不是很多。在ES出现之后,ES的社区火爆程度直线上升,ES的文档非常健全。
- ES对现在云计算和大数据支持的特别好。
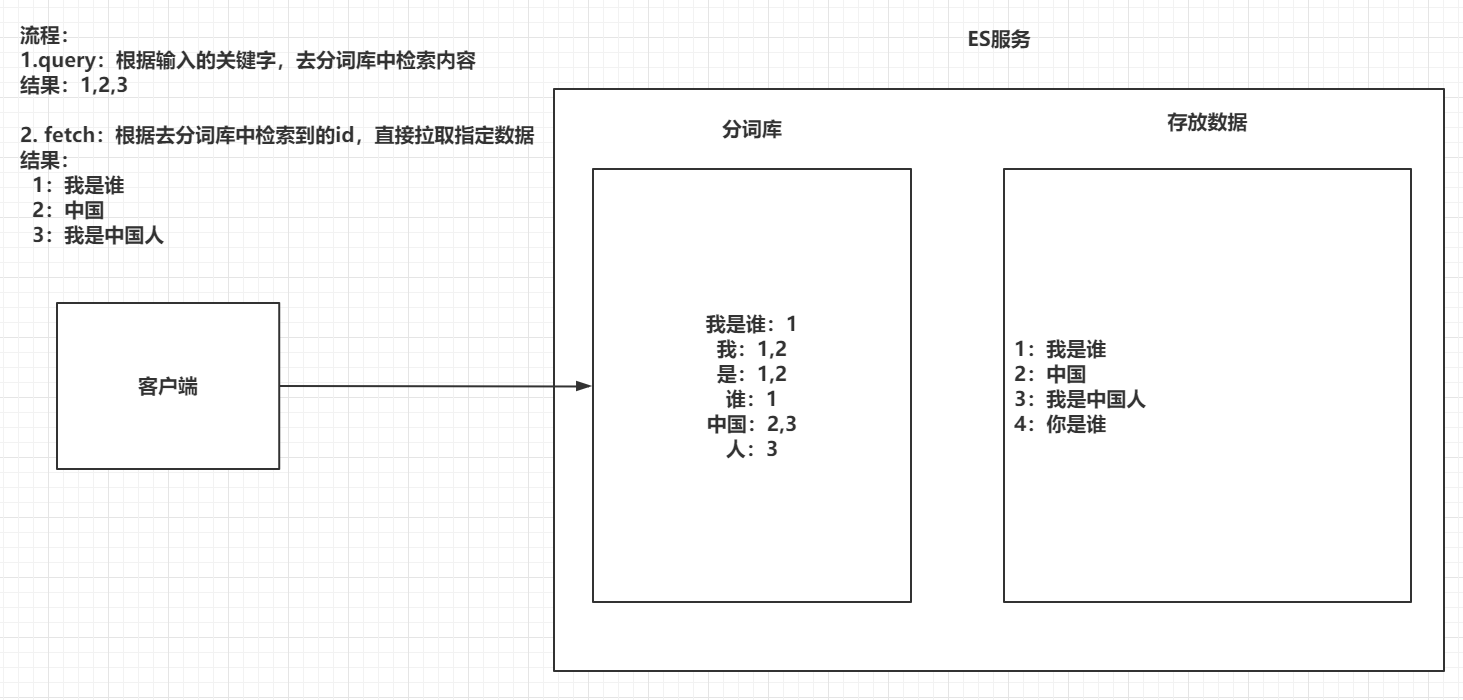
2.4 倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
当用户去查询数据时,会将用户的查询关键字进行分词。
然后去分词库中匹配内容,最终得到数据的id标识。
根据id标识去存放数据的位置拉取到指定的数据。
检索的时候 先将检索的内容分词 然后 去分词库匹配 拿到匹配数据的索引 再根据索引去数据存储的位置 拿到匹配的数据
elk elasticsearch (存储分析检索数据) + logstash (采集数据) + kibana (展示数据的图形化界面)
| 倒排索引 |
|---|
 |
2.5基本概念
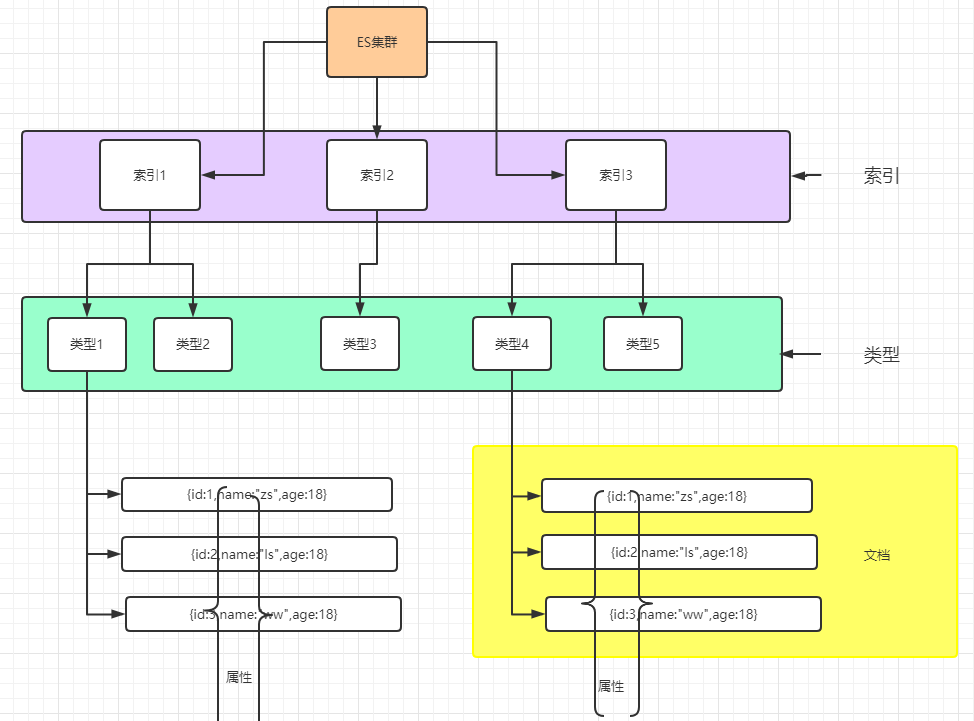
2.4.1 Index (索引)
动词 ,相当于Mysql 中的insert
名词, 相当于Mysql 中的 Database
2.4.2 Type (类型)
在Index(索引)中 ,可以定义一个或多个类型。
类似Mysql 中的table ,每一种类型的数据放在一起
2.4.3 Document (文档)
保存在某个索引(index)下,某种类型(type)的一个数据(Document) ,文档是json 格式的,Document 就像是Mysql 中某个table里面的内容。
三、 ElasticSearch安装
3.1 安装ES&Kibana 不建议
1.下载镜像文件
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
2.创建挂载目录
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
3.启动容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx1024m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
#如果 启动elasticsearch 失败, 查看 日期 docker logs 容器id 查看 某容器的日志
#docker logs 容器id
# 需要 给 elasticsearch 目录授权
#chmod -R 777 /mydata/elasticsearch/ 给整个目录授权 可读可写可执行
#在启动容器 应该就好了
4.启动kibana
docker run --name kibana -e ELASTICSEARCH_URL=http://192.168.5.202:9200 -p 5601:5601\
-d kibana:7.4.2
测试访问
http://192.168.5.202:9200 如访问不到 查看日志
http://192.168.5.202:5601 如访问不到 查看日志 看容器内 kibana.yml 中 ip 地址是否正确3.1.1 使用docker-compose的方式安装(推荐)
mkdir -p /opt/docker_compose/elasticsearch/config mkdir -p /opt/docker_compose/elasticsearch/data
echo "http.host: 0.0.0.0" >> /opt/docker_compose/elasticsearch/config/elasticsearch.yml
version: "3.1"
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:7.4.2
restart: always
container_name: elasticsearch
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- /opt/docker_elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /opt/docker_elasticsearch/data:/usr/share/elasticsearch/data
- /opt/docker_elasticsearch/plugins:/usr/share/elasticsearch/plugins
ports:
- 9200:9200
- 9300:9300
kibana:
image: kibana:7.4.2
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.133.103:9200
depends_on:
- elasticsearch9300 端口 为 es 集群间组件的通信端口,9200 端口为浏览器访问的http 协议resetful 端口
记得 给文件夹授权 授权之后 再docker-compose up
chmod 777 config
chmod 777 data
如果 访问 http://192.168.199.109:9200 失败 查看日志 是否vm内存配置过小 elasticsearch启动时遇到的错误
问题翻译过来就是:elasticsearch用户拥有的内存权限太小,至少需要262144;解决办法1:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144 把宿主机内存配大一些
解决办法2 启动时 指定内存 咱们的安装方法 就是启动时 指定内存
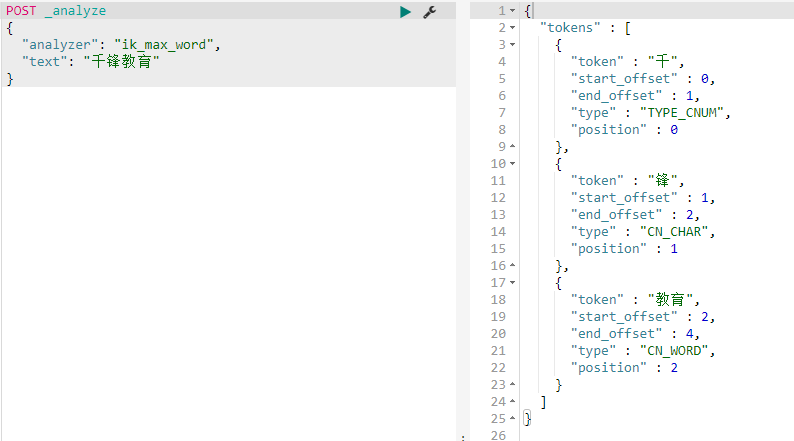
3.2 安装IK分词器
ik 分词器 就是 elasticsearch 的一个插件
- 下载IK分词器的地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 进去到ES容器内部,跳转到bin目录下,执行bin目录下的脚本文件:
- ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 重启ES的容器,让IK分词器生效。
注意: 如果 在线安装太慢的话 可以先下载下来 压缩包 然后手动安装
把下载的压缩 包 解压到 挂载目录 plugins 下的 ik 文件夹里,
cd /mydata/elasticsearch/plugins
mkdir ik
cd ik 先把压缩包 放在 ik 目录中
unzip elasticsearch-analysis-ik-7.4.2.zip 解压完之后 可以把 压缩包删掉 rm -rf *.zip
进入容器内部 bin 目录下 执行 elasticsearch-plugin list 查看 插件列表 有没有 ik
ik_max_word 是ik 分词器 的 一种分词方式 还有别的分词方式 后面遇到再说
| 校验IK分词器 |
|---|
 |
四、 ElasticSearch基本操作
4.1 ES的结构 --- 操作es 之前 先了解es 的结构
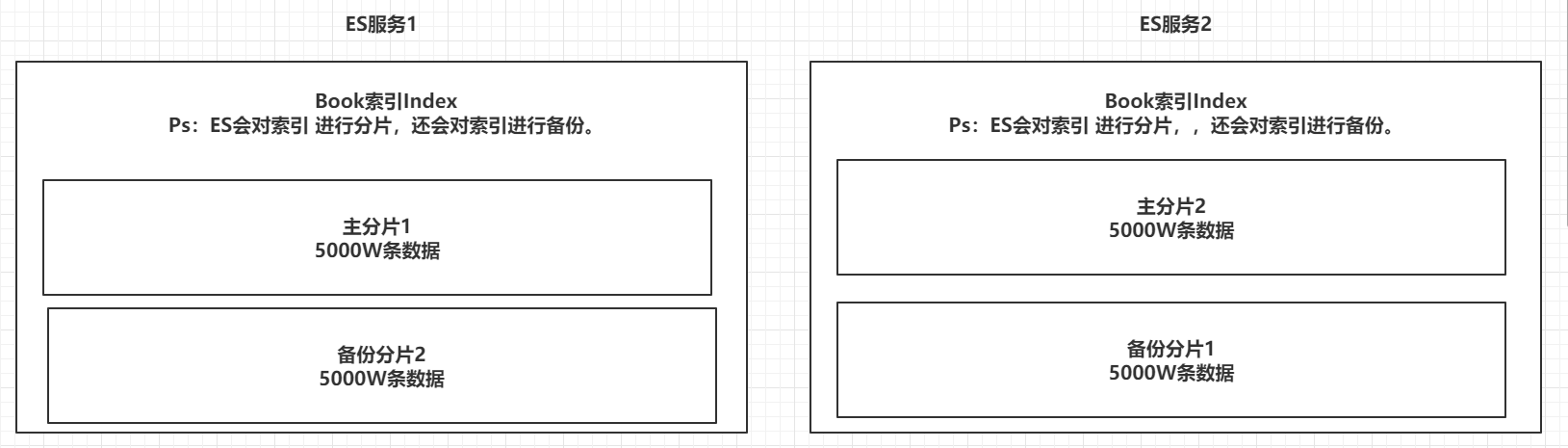
4.1.1 索引Index,分片和备份
ES的服务中,可以创建多个索引。
每一个索引默认被分成5片存储。
每一个分片都会存在至少一个备份分片。
备份分片默认不会帮助检索数据,当ES检索压力特别大的时候,备份分片才会帮助检索数据。
备份的分片必须放在不同的服务器中。
理解: 索引index是es 中最大的数据存储单位 ,和mysql 的区别是 一个索引(index)中可以存海量(几亿条)数据 ,如果我们要在几亿条数据中检索出几条想要的数据 效率会很低 所以 es 提供了 一种对索引进行分片的机制 ,ES 天然支持集群,在集群服务器中 ES 把一个索引进行分片 放在不同的服务器上 如下图 例如 有一亿条数据 分成两个分片 每个分片上有5000万条数据 这样做的好处 一是 提高查询速度 二是 提高数据的存储量,另外 为了保证数据的安全 每个主分片会有备份分片 主分片和备份分片在不同的服务器上 , 比如 主分片2 挂掉了 在 ES服务1 上面 还有 主分片2的备份分片 ,这样在一定程度上保证了数据的安全性 避免数据的丢失。但是 如果 当前集群中 只有一台es服务器 那么 这台服务器上 放的都是主分片,没有备份分片,什么时候扩展了集群中的 另一台服务器 才会存放备份分片。
| 索引分片备份 |
|---|
 |
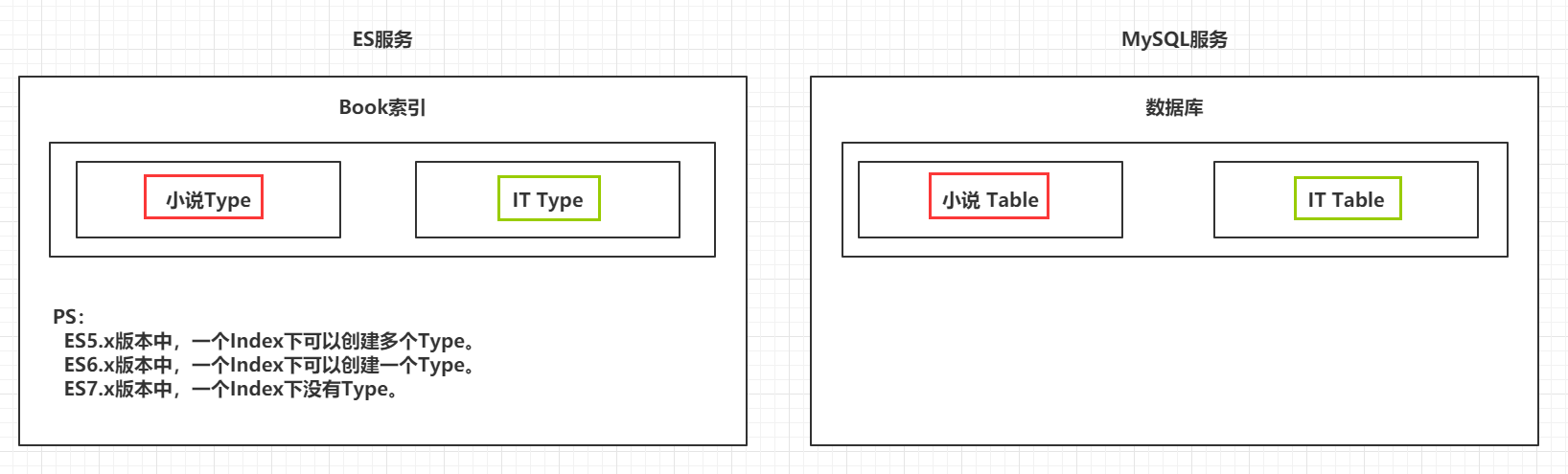
4.1.2 类型 Type
一个索引下,可以创建多个类型。
es7 版本 不推荐使用type ,但是还是能用,到后面的es 版本 就不能再使用type 了
| 类型 |
|---|
 |
4.1.3 文档 Doc
一个类型下,可以有多个文档。这个文档就类似于MySQL表中的多行数据。
| 文档 |
|---|
 |
4.1.4 属性 Field
一个文档中,可以包含多个属性。类似于MySQL表中的一行数据存在多个列。
| 属性 |
|---|
 |
4.2 操作ES的RESTful语法
GET请求:
http://ip:port/_cat/nodes:查看所有节点 在kibana 中使用 GET _cat/nodes
http://ip:port/_cat/health:查看es 健康状况
http://ip:port/_cat/master:查看主节点
http://ip:port/_cat/indices:查看所有索引 相当于 show databases;
http://ip:port/index:查询索引信息 GET book 相当于查看 数据库表结构
http://ip:port/index/type/doc_id:查询指定的文档信息注意 咱们用的是 es 7 直接使用type 的 话 会给出警告信息 ,咱们使用 _doc 代替 type
比如 查询指定文档信息 GET book/_doc/1 查询 book 索引中 id 为1 的文档信息
shellGET book/_doc/2POST请求:
http://ip:port/index/type/doc_idshell# 指定文档id的添加操作 如果索引还未创建 还可以创建索引 POST book/_doc/2 { "name":"西游记", "author":"吴承恩" }
http://ip:port/index/type/_search:查询文档,可以在请求体中添加json字符串来代表查询条件# 查询操作 POST book/_search { "query":{ "match": { "name": "西游记" } } }
http://ip:port/index/type/doc_id/_update:修改文档,在请求体中指定json字符串代表修改的具体信息 注意 带 _update 的 修改 json 格式 里需要加 doc 对比 本文档下面的案例说明POST book/_update/1 # 修改操作 { "doc":{ "name":"大奉打更2人",
"author":"xxxxx2" } }PUT请求:
http://ip:port/index:创建一个索引,也可以在请求体中指定索引的信息,类型,结构PUT book2 # 创建一个叫 book2 的索引 执行第二次会报错
# 添加或修改文档 第一次是添加(同样 索引不存在 也会创建索引) 后面再执行是修改PUT book3/_doc/1 { "name":"java" }
- `http://ip:port/index/type/_mappings`:代表创建索引时,指定索引文档存储的属性的信息
DELETE请求: -
http://ip:port/index:删除索引DELETE book2 # 删除book2 索引
http://ip:port/index/type/doc_id:删除指定的文档DELETE book/_doc/2 删除索引book中 id 为2 的文档
4.3 索引的操作
4.3.1 创建一个索引
语法如下 先创建一个最简单的 先不指定他的结构化数据
# 创建一个索引
PUT /person
{
"settings": {
"number_of_shards": 5, # 分片 数5
"number_of_replicas": 1 # 备份
}
}4.3.2 查看索引信息
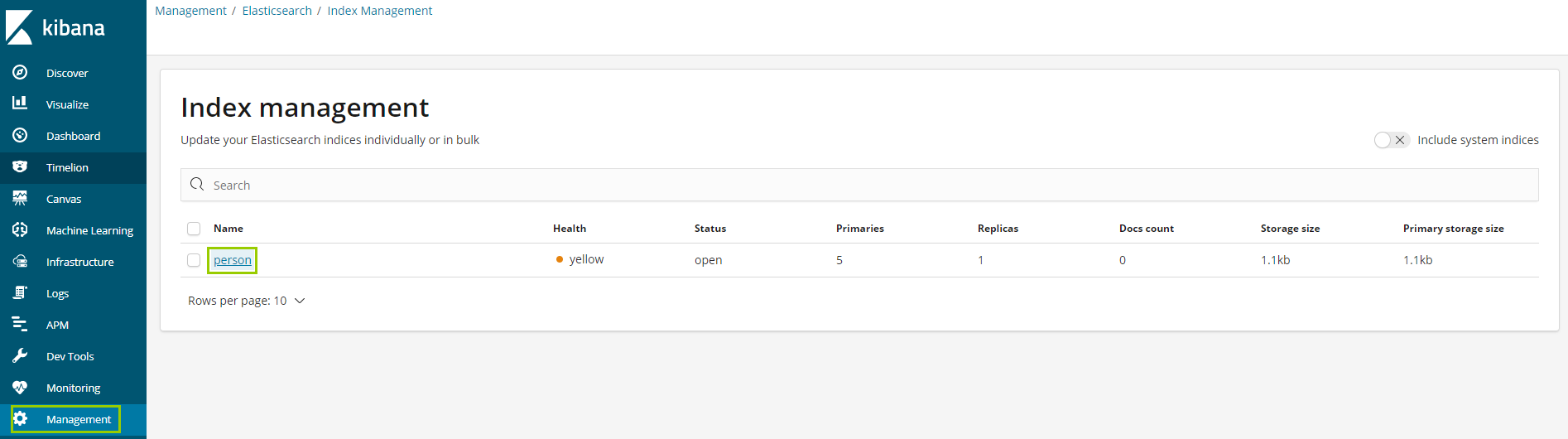
语法如下 去management 中 查看索引信息
Primaries 意思是 分片
Replicas 意思是备份
Health 健康状态黄色 表示不太健康 因为现在es 集群中只有一台服务器 备份分片没有地方存放 所以是黄色的健康状态, 如果 集群中有多台服务器 备份分片 就可以存储在别的服务器上 避免这台服务器挂掉 数据丢失问题
点索引的名字 可以查看索引的详细信息
# 查看索引信息
GET /person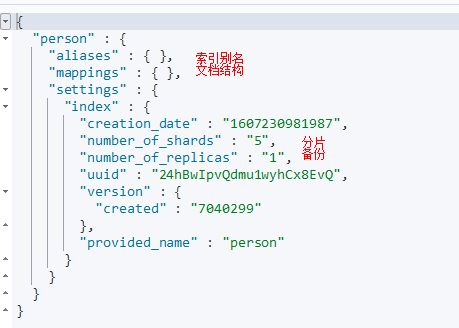
| 查看信息 |
|---|
 |
4.3.3 删除索引
语法如下
# 删除索引
DELETE /person4.4 ES中Field可以指定的类型
字符串类型:
- text:一般被用于全文检索。 将当前Field进行分词。
- keyword:当前Field不会被分词。
数值类型:
- long:取值范围为-9223372036854774808~922337203685477480(-2的63次方到2的63次方-1),占用8个字节
- integer:取值范围为-2147483648~2147483647(-2的31次方到2的31次方-1),占用4个字节
- short:取值范围为-32768~32767(-2的15次方到2的15次方-1),占用2个字节
- byte:取值范围为-128~127(-2的7次方到2的7次方-1),占用1个字节
- double:1.797693e+308~ 4.9000000e-324 (e+308表示是乘以10的308次方,e-324表示乘以10的负324次方)占用8个字节
- float:3.402823e+38 ~ 1.401298e-45(e+38表示是乘以10的38次方,e-45表示乘以10的负45次方),占用4个字节
- half_float:精度比float小一半。
- scaled_float:根据一个long和scaled来表达一个浮点型,long-345,scaled-100 -> 3.45
时间类型:
- date类型,针对时间类型指定具体的格式
布尔类型:
- boolean类型,表达true和false
二进制类型:
- binary类型暂时支持Base64 encode string
范围类型:
- long_range:赋值时,无需指定具体的内容,只需要存储一个范围即可,指定gt,lt,gte,lte
- integer_range:同上
- double_range:同上
- float_range:同上
- date_range:同上
- ip_range:同上
经纬度类型:
- geo_point:用来存储经纬度的
ip类型:
- ip:可以存储IPV4或者IPV6
其他的数据类型参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.6/mapping-types.html
4.5 创建索引并指定数据结构
语法如下
# 创建索引,指定数据结构
PUT /book
{
"settings": {
# 分片数
"number_of_shards": 5,
# 备份数
"number_of_replicas": 1
},
# 指定数据结构
"mappings": {
# 类型 Type es 7 可以把这个删了
"novel": {
# 文档存储的Field
"properties": {
# Field属性名
"name": {
# 类型
"type": "text",
# 指定分词器 # 在对这个属性做分词的时候 使用 ik分词器
"analyzer": "ik_max_word",
# 指定当前Field可以被作为查询的条件 如果为false 则不能作为查询条件
"index": true ,
# 当前field是否需要额外存储 一般设置为false 即可 不需要额外存储
"store": false
},
"author": {
# keyword 也算是字符串类型
"type": "keyword"
},
"count": {
"type": "long"
},
"on-sale": {
"type": "date",
# 时间类型的格式化方式
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"descr": {
"type": "text",
# 在对这个属性做分词的时候 使用 ik分词器
"analyzer": "ik_max_word"
}
}
}
}
}4.6 文档的操作
文档在ES服务中的唯一标识,
_index,_type,_id三个内容为组合,锁定一个文档,操作是添加还是修改。
4.6.1 新建文档
自动生成_id
# 添加文档,自动生成id 不推荐这种自动生成的id
POST /book/_doc
{
"name": "盘龙",
"author": "我吃西红柿",
"count": 100000,
"on-sale": "2000-01-01",
"descr": "山重水复疑无路,柳暗花明又一村"
}手动指定_id
# 添加文档,手动指定id 推荐使用
PUT /book/_doc/1
{
"name": "红楼梦",
"author": "曹雪芹",
"count": 10000000,
"on-sale": "1985-01-01",
"descr": "一个是阆苑仙葩,一个是美玉无瑕"
}4.6.2 修改文档
覆盖式修改
# 修改文档 覆盖式修改 如果没有指定某个属性 这个属性会被覆盖掉 覆盖没了
PUT /book/novel/1
{
"name": "红楼梦",
"author": "曹雪芹",
"count": 4353453,
"on-sale": "1985-01-01",
"descr": "一个是阆苑仙葩,一个是美玉无瑕"
}doc修改方式
# 修改文档,基于doc方式 不会覆盖之前的内容 指定哪一个属性 修改哪一个属性
POST /book/novel/1/_update # 7 之前的写法
{
"doc": {
# 指定上需要修改的field和对应的值
"count": "1234565"
}
}
# 现在 都这样写
POST book/_update/1
{
"doc":{
"name": "斗破苍穹"
}
}4.6.3 删除文档
根据id删除
# 根据id删除文档
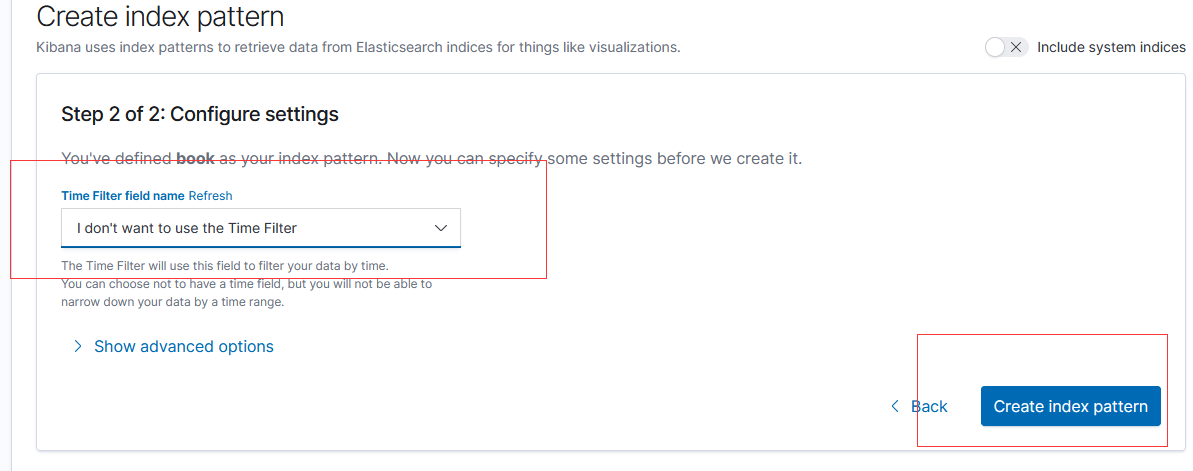
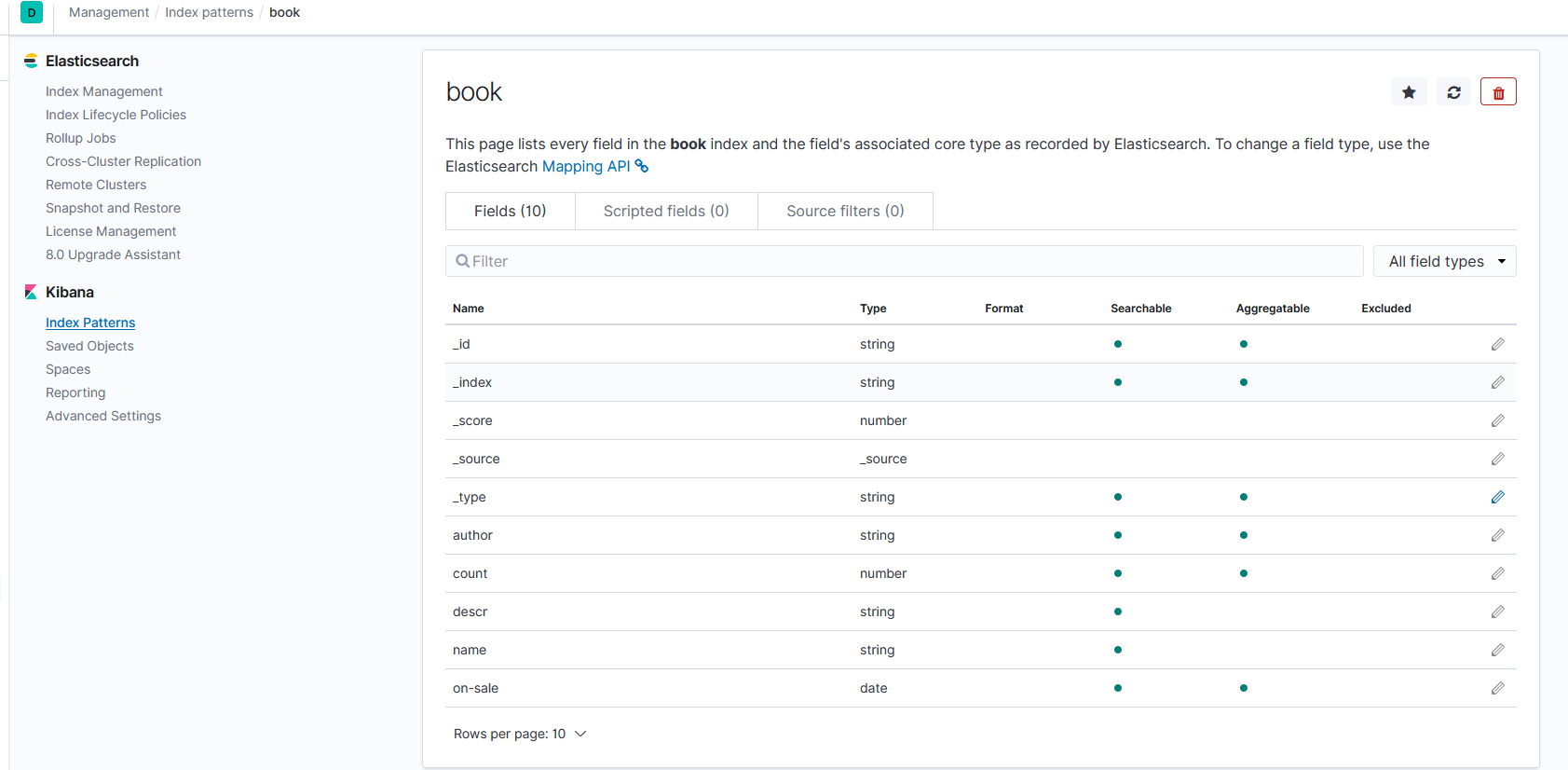
DELETE book/_doc/1 # 删除id 为1 的文档4.6.4 补充
在kibana 可视化界面中可以看到 创建的索引信息


五、Java操作ElasticSearch【重点】
5.1 Java连接ES
创建springboot工程
导入依赖
这里注意 springboot版本 默认了es 的 一些版本,需要咱们自己统一定义 要不然会有版本冲突 所以 在pom 文件中 统一 es 版本
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
<dependencies>
<!-- elasticsearch -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.4.2</version>
</dependency>
<!-- elasticsearch 高阶API-->
<dependency>
<!--导入 es 的 高阶 api 来 操作 es
要进行配置
如果使用spsringdata 操作es 配置会比较简单 只需要在配置文件指定es 的地址就好了
我们是自己配的 所以自己对es 做配置
-->
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
<!-- 3. junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- 4. lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.22</version>
</dependency>
</dependencies>创建配置类,测试连接ES
package com.glls.esdemo.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author glls
*/
@Configuration
public class ElasticSearchConfig {
//RequestOptions 这个类 主要封装了 访问 ES 的 一些头信息 一些 设置信息
public static final RequestOptions COMMON_OPTIONS;
static {
// 请求设置项
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization","Bearer"+TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30*1024*1024*1024));
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient(){
RestClientBuilder builder = null;
builder = RestClient.builder(new HttpHost("192.168.5.205",9200,"http"));
RestHighLevelClient client = new RestHighLevelClient(builder);
//RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")));
return client;
}
}
// 测试 能不能得到 RestHighLevelClient
@SpringBootTest
class EsdemoApplicationTests {
@Resource
private RestHighLevelClient client;
@Test
void contextLoads() {
System.out.println(client);
}
}5.2 Java操作索引
5.2.1 创建索引
代码如下
/**
* 索引的创建
*
* */
/**
* {
* "properties":{
* "name":{
* "type":"text"
* },
* "age":{
* "type":"integer"
* },
* "birthday":{
* "type":"date",
* "format":"yyyy-MM-dd"
* }
* }
*
* }
*
* */
@Test
public void demo1() throws IOException {
// 创建索引
String index = "person";
//1. 准备关于索引的settings
Settings.Builder settings = Settings.builder()
.put("number_of_shards", 3)
.put("number_of_replicas", 1);
//2. 准备关于索引的结构mappings
XContentBuilder mappings = JsonXContent.contentBuilder()
.startObject() // 和 endObject 成对出现
.startObject("properties")
.startObject("name")
.field("type","text")
.endObject()
.startObject("age")
.field("type","integer")
.endObject()
.startObject("birthday")
.field("type","date")
.field("format","yyyy-MM-dd")
.endObject()
.endObject()
.endObject();
//3. 将settings和mappings封装到一个Request对象
// 不同的操作 准备的request 对象不一样 与下文对比
CreateIndexRequest request = new CreateIndexRequest(index)
.settings(settings)
.mapping(mappings);// 如果是6版本 还需要在这个方法指定type //.mapping(type,mappings)
//4. 通过client对象去连接ES并执行创建索引
// 通过client 对象 把上面准备的 request 对象 发到es执行
CreateIndexResponse resp = client.indices().create(request, RequestOptions.DEFAULT);
//5. 输出
System.out.println("resp:" + resp.toString());
}5.2.2 检查索引是否存在
代码如下
/**
* 判断 索引是否存在
* */
@Test
public void demo2() throws IOException {
//1. 准备request对象
String index = "person";
GetIndexRequest request = new GetIndexRequest(index);
//2. 通过client去操作
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
//3. 输出
System.out.println(exists);
}5.2.3 删除索引
代码如下
@Test
public void delete() throws IOException {
//1. 准备request对象
DeleteIndexRequest request = new DeleteIndexRequest();
request.indices(index);
//2. 通过client对象执行
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//3. 获取返回结果
System.out.println(delete.isAcknowledged());
}5.3 Java操作文档
5.3.1 添加文档操作
代码如下
// 添加fastjson 依赖, jackson 也可以 用法大致一样
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.72</version>
</dependency>
// 创建实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class Person {
private Integer id;
private String name;
private Integer age;
@JSONField(format = "yyyy-MM-dd") // fastjson 转换对象时 对日期类型字段的 格式转换
private Date birthday;
}
// 测试方法
/**
* 添加文档
*
* */
@Test
public void demo4() throws IOException {
String index = "person";
//1. 准备一个json数据
Person person = new Person(1,"张三",23,new Date());
//2. 准备一个request对象(手动指定id)
IndexRequest request = new IndexRequest(index);
request.id(person.getId().toString());
String json = JSON.toJSONString(person);
System.out.println(json);
request.source(json, XContentType.JSON);
//3. 通过client对象执行添加
IndexResponse resp = client.index(request, RequestOptions.DEFAULT);
//4. 输出返回结果
System.out.println(resp.getResult().toString());
}
//添加doc 方式2
@Test
public void testAddDoc2() throws IOException {
HashMap<String, Object> map = new HashMap<>();
map.put("id",2);
map.put("name","李四");
map.put("age",22);
map.put("birthday","1999-11-11");
//构建 request 对象
IndexRequest request = new IndexRequest(index);
request.id(map.get("id").toString());
request.source(map);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult().toString());
}5.3.2 修改文档
代码如下
/**
* 修改文档
* */
@Test
public void demo5() throws IOException {
String index = "person";
//1. 创建一个Map,指定需要修改的内容
Map<String,Object> doc = new HashMap<>();
doc.put("name","张大三");
String docId = "1";
//2. 创建request对象,封装数据
UpdateRequest request = new UpdateRequest(index,docId);
request.doc(doc);
//3. 通过client对象执行
UpdateResponse update = client.update(request, RequestOptions.DEFAULT);
//4. 输出返回结果
System.out.println(update.getResult().toString());
}- 准备条件数据
- 构建reuqest
- 封装数据到request
- client 发送请求 得到结果
- 解析结果
5.3.3 删除文档
代码如下
@Test
public void deleteDoc() throws IOException {
//1. 封装Request对象
DeleteRequest request = new DeleteRequest(index,"1");
//2. client执行
DeleteResponse resp = client.delete(request, RequestOptions.DEFAULT);
//3. 输出结果
System.out.println(resp.getResult().toString());
}5.4 Java批量操作文档
5.4.1 批量添加
代码如下
/**
* 批量添加
*
* */
@Test
public void bulkCreateDoc() throws IOException {
String index="person";
//1. 准备多个json数据
Person p1 = new Person(3,"王五",23,new Date());
Person p2 = new Person(4,"赵六",24,new Date());
Person p3 = new Person(5,"田七",25,new Date());
String json1 = JSON.toJSONString(p1);
String json2 = JSON.toJSONString(p2);
String json3 = JSON.toJSONString(p3);
//2. 创建Request,将准备好的数据封装进去
BulkRequest request = new BulkRequest();
request.add(new IndexRequest(index).id(p1.getId().toString()).source(json1,XContentType.JSON));
request.add(new IndexRequest(index).id(p2.getId().toString()).source(json2,XContentType.JSON));
request.add(new IndexRequest(index).id(p3.getId().toString()).source(json3,XContentType.JSON));
//3. 用client执行
BulkResponse resp = client.bulk(request, RequestOptions.DEFAULT);
//4. 输出结果
System.out.println(resp.toString());
}5.4.2 批量删除
代码如下
@Test
public void bulkDeleteDoc() throws IOException {
//1. 封装Request对象
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest(index,type,"1"));
request.add(new DeleteRequest(index,type,"2"));
request.add(new DeleteRequest(index,type,"3"));
//2. client执行
BulkResponse resp = client.bulk(request, RequestOptions.DEFAULT);
//3. 输出
System.out.println(resp);
}5.5 ElasticSearch练习
创建索引,指定数据结构
索引名:sms-logs-index
类型名:sms-logs-type
结构如下:
| 索引结构图 |
|---|
 |
5.5.1代码
实体类
package com.glls.esdemo.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
/**
* @author glls
* @email 524840158@qq.com
* @company xxx
* @create 2020-10-26 22:55
*
*
* 准备 测试练习数据
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class SmsLogs {
// 唯一ID
private String id;
// 创建时间
private Date createDate;
private Date sendDate; // 发送时间
private String longCode; // 发送的长号码
private String mobile; // 下发手机号
private String corpName; // 发送公司名称
private String smsContent; // 下发短信内容
private Integer state; // 短信下发状态 0 成功 1 失败
private Integer operatorId; // 运营商编号 1 移动 2 联通 3 电信
private String province; // 省份
private String ipAddr; // 下发服务器IP地址
private Integer replyTotal; // 短信状态报告返回时长(秒)
private Integer fee; // 费用
}测试数据
package com.glls.esdemo;
import com.alibaba.fastjson.JSON;
import com.glls.esdemo.pojo.SmsLogs;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.common.xcontent.json.JsonXContent;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.io.IOException;
import java.util.Date;
/**
*
* 检索操作
* */
@SpringBootTest
class EsdemoApplicationTests2 {
@Resource
private RestHighLevelClient client;
String index = "sms-logs-index";
@Test
public void createSmsLogsIndex() throws IOException {
//1. settings
Settings.Builder settings = Settings.builder()
.put("number_of_shards", 3)
.put("number_of_replicas", 1);
//2. mapping.
XContentBuilder mapping = JsonXContent.contentBuilder()
.startObject()
.startObject("properties")
.startObject("createDate")
.field("type", "date")
.endObject()
.startObject("sendDate")
.field("type", "date")
.endObject()
.startObject("longCode")
.field("type", "keyword")
.endObject()
.startObject("mobile")
.field("type", "keyword")
.endObject()
.startObject("corpName")
.field("type", "keyword")
.endObject()
.startObject("smsContent")
.field("type", "text")
.field("analyzer", "ik_max_word")
.endObject()
.startObject("state")
.field("type", "integer")
.endObject()
.startObject("operatorId")
.field("type", "integer")
.endObject()
.startObject("province")
.field("type", "keyword")
.endObject()
.startObject("ipAddr")
.field("type", "ip")
.endObject()
.startObject("replyTotal")
.field("type", "integer")
.endObject()
.startObject("fee")
.field("type", "long")
.endObject()
.endObject()
.endObject();
//3. 添加索引.
CreateIndexRequest request = new CreateIndexRequest(index);
request.settings(settings);
request.mapping(mapping);
CreateIndexResponse resp = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println("resp:" + resp.toString());
System.out.println("OK!!");
}
@Test
public void addTestData() throws IOException {
BulkRequest request = new BulkRequest();
SmsLogs smsLogs = new SmsLogs();
smsLogs.setMobile("13800000000");
smsLogs.setCorpName("途虎养车");
smsLogs.setCreateDate(new Date());
smsLogs.setSendDate(new Date());
smsLogs.setIpAddr("10.126.2.9");
smsLogs.setLongCode("10690000988");
smsLogs.setReplyTotal(10);
smsLogs.setState(0);
smsLogs.setSmsContent("【途虎养车】亲爱的张三先生/女士,您在途虎购买的货品(单号TH123456)已 到指定安装店多日," + "现需与您确认订单的安装情况,请点击链接按实际情况选择(此链接有效期为72H)。您也可以登录途 虎APP进入" + "“我的-待安装订单”进行预约安装。若您在服务过程中有任何疑问,请致电400-111-8868向途虎咨 询。");
smsLogs.setProvince("北京");
smsLogs.setOperatorId(1);
smsLogs.setFee(3);
request.add(new IndexRequest(index).id("21").source(JSON.toJSONString(smsLogs), XContentType.JSON));
smsLogs.setMobile("13700000001");
smsLogs.setProvince("上海");
smsLogs.setSmsContent("【途虎养车】亲爱的刘红先生/女士,您在途虎购买的货品(单号TH1234526)已 到指定安装店多日," + "现需与您确认订单的安装情况,请点击链接按实际情况选择(此链接有效期为72H)。您也可以登录途 虎APP进入" + "“我的-待安装订单”进行预约安装。若您在服务过程中有任何疑问,请致电400-111-8868向途虎咨 询。");
request.add(new IndexRequest(index).id("22").source(JSON.toJSONString(smsLogs), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs1 = new SmsLogs();
smsLogs1.setMobile("13100000000");
smsLogs1.setCorpName("盒马鲜生");
smsLogs1.setCreateDate(new Date());
smsLogs1.setSendDate(new Date());
smsLogs1.setIpAddr("10.126.2.9");
smsLogs1.setLongCode("10660000988");
smsLogs1.setReplyTotal(15);
smsLogs1.setState(0);
smsLogs1.setSmsContent("【盒马】您尾号12345678的订单已开始配送,请在您指定的时间收货不要走开 哦~配送员:" + "刘三,电话:13800000000");
smsLogs1.setProvince("北京");
smsLogs1.setOperatorId(2);
smsLogs1.setFee(5);
request.add(new IndexRequest(index).id("23").source(JSON.toJSONString(smsLogs1), XContentType.JSON));
smsLogs1.setMobile("18600000001");
smsLogs1.setProvince("上海");
smsLogs1.setSmsContent("【盒马】您尾号7775678的订单已开始配送,请在您指定的时间收货不要走开 哦~配送员:" + "王五,电话:13800000001");
request.add(new IndexRequest(index).id("24").source(JSON.toJSONString(smsLogs1), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs2 = new SmsLogs();
smsLogs2.setMobile("15300000000");
smsLogs2.setCorpName("滴滴打车");
smsLogs2.setCreateDate(new Date());
smsLogs2.setSendDate(new Date());
smsLogs2.setIpAddr("10.126.2.8");
smsLogs2.setLongCode("10660000988");
smsLogs2.setReplyTotal(50);
smsLogs2.setState(1);
smsLogs2.setSmsContent("【滴滴单车平台】专属限时福利!青桔/小蓝月卡立享5折,特惠畅骑30天。" + "戳 https://xxxxxx退订TD");
smsLogs2.setProvince("上海");
smsLogs2.setOperatorId(3);
smsLogs2.setFee(7);
request.add(new IndexRequest(index).id("25").source(JSON.toJSONString(smsLogs2), XContentType.JSON));
smsLogs2.setMobile("18000000001");
smsLogs2.setProvince("武汉");
smsLogs2.setSmsContent("【滴滴单车平台】专属限时福利!青桔/小蓝月卡立享5折,特惠畅骑30天。" + "戳 https://xxxxxx退订TD");
request.add(new IndexRequest(index).id("26").source(JSON.toJSONString(smsLogs2), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs3 = new SmsLogs();
smsLogs3.setMobile("13900000000");
smsLogs3.setCorpName("招商银行");
smsLogs3.setCreateDate(new Date());
smsLogs3.setSendDate(new Date());
smsLogs3.setIpAddr("10.126.2.8");
smsLogs3.setLongCode("10690000988");
smsLogs3.setReplyTotal(50);
smsLogs3.setState(0);
smsLogs3.setSmsContent("【招商银行】尊贵的李四先生,恭喜您获得华为P30 Pro抽奖资格,还可领100 元打" + "车红包,仅限1天");
smsLogs3.setProvince("上海");
smsLogs3.setOperatorId(1);
smsLogs3.setFee(8);
request.add(new IndexRequest(index).id("27").source(JSON.toJSONString(smsLogs3), XContentType.JSON));
smsLogs3.setMobile("13990000001");
smsLogs3.setProvince("武汉");
smsLogs3.setSmsContent("【招商银行】尊贵的李四先生,恭喜您获得华为P30 Pro抽奖资格,还可领100 元打" + "车红包,仅限1天");
request.add(new IndexRequest(index).id("28").source(JSON.toJSONString(smsLogs3), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs4 = new SmsLogs();
smsLogs4.setMobile("13700000000");
smsLogs4.setCorpName("中国平安保险有限公司");
smsLogs4.setCreateDate(new Date());
smsLogs4.setSendDate(new Date());
smsLogs4.setIpAddr("10.126.2.8");
smsLogs4.setLongCode("10690000998");
smsLogs4.setReplyTotal(18);
smsLogs4.setState(0);
smsLogs4.setSmsContent("【中国平安】奋斗的时代,更需要健康的身体。中国平安为您提供多重健康保 障,在奋斗之路上为您保驾护航。退订请回复TD");
smsLogs4.setProvince("武汉");
smsLogs4.setOperatorId(1);
smsLogs4.setFee(5);
request.add(new IndexRequest(index).id("29").source(JSON.toJSONString(smsLogs4), XContentType.JSON));
smsLogs4.setMobile("13990000002");
smsLogs4.setProvince("武汉");
smsLogs4.setSmsContent("【招商银行】尊贵的王五先生,恭喜您获得iphone 56抽奖资格,还可领5 元打" + "车红包,仅限100天");
request.add(new IndexRequest(index).id("30").source(JSON.toJSONString(smsLogs4), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs5 = new SmsLogs();
smsLogs5.setMobile("13600000000");
smsLogs5.setCorpName("中国移动");
smsLogs5.setCreateDate(new Date());
smsLogs5.setSendDate(new Date());
smsLogs5.setIpAddr("10.126.2.8");
smsLogs5.setLongCode("10650000998");
smsLogs5.setReplyTotal(60);
smsLogs5.setState(0);
smsLogs5.setSmsContent("【北京移动】尊敬的客户137****0000,5月话费账单已送达您的139邮箱," + "点击查看账单详情 http://y.10086.cn/; " + " 回Q关闭通知,关注“中国移动139邮箱”微信随时查账单【中国移动 139邮箱】");
smsLogs5.setProvince("武汉");
smsLogs5.setOperatorId(1);
smsLogs5.setFee(4);
request.add(new IndexRequest(index).id("31").source(JSON.toJSONString(smsLogs5), XContentType.JSON));
smsLogs5.setMobile("13990001234");
smsLogs5.setProvince("山西");
smsLogs5.setSmsContent("【北京移动】尊敬的客户137****1234,8月话费账单已送达您的126邮箱,\" + \"点击查看账单详情 http://y.10086.cn/; \" + \" 回Q关闭通知,关注“中国移动126邮箱”微信随时查账单【中国移动 126邮箱】");
request.add(new IndexRequest(index).id("32").source(JSON.toJSONString(smsLogs5), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
client.bulk(request,RequestOptions.DEFAULT);
System.out.println("OK!");
}
}六、 ElasticSearch的各种查询
6.1 term&terms查询【重点】
6.1.1 term查询
term的查询是代表完全匹配,搜索之前不会对你搜索的关键字进行分词,对你的关键字去文档分词库中去匹配内容。
# term查询
POST /sms-logs-index/sms-logs-type/_search
{
"from": 0, # limit ?
"size": 5, # limit x,?
"query": {
"term": { # 完整匹配
"province": {
"value": "北京" # 拿这个 北京 去完整匹配 不会分词匹配
}
}
}
}
#注意 这里对 term 的理解 即 对 field 类型 text 和 keyword 的理解 ,term 是拿这个查询条件不进行分词 去匹配 文档中的内容, 而文档中的内容 如果是text 类型,会对这个 field 进行分词 ,如果分词后的内容 没有和 term 的 查询条件匹配上 ,那么term 查询 就查不出来结果, 如果文档中的内容 是 keyword ,就不会对文档中的进行分词,此时 就需要term 的完整匹配查询 才能查到数据。 总结 term 不对查询条件进行分词, field是text或者keyword 类型 分别是 对文档内容分词(text)和不分词(keyword)
# 查询结果
{
"took" : 2, # 查询用了2毫秒
"timed_out" : false, # 是否超时 没有超时
"_shards" : { # 分片信息
"total" : 3, # 一共使用三个分片
"successful" : 3, # 成功了三个分片
"skipped" : 0, # 跳过
"failed" : 0 # 失败
},
"hits" : { # 查询命中
"total" : { # 总命中
"value" : 2, # 命中数
"relation" : "eq" # 查询关系
},
"max_score" : 0.6931472, # 匹配分数 匹配度越高 分数越高
"hits" : [
{
"_index" : "sms-logs-index",
"_type" : "_doc",
"_id" : "21",
"_score" : 0.6931472,
"_source" : {
"corpName" : "途虎养车",
"createDate" : 1607833538978,
"fee" : 3,
"ipAddr" : "10.126.2.9",
"longCode" : "10690000988",
"mobile" : "13800000000",
"operatorId" : 1,
"province" : "北京",
"replyTotal" : 10,
"sendDate" : 1607833538978,
"smsContent" : "【途虎养车】亲爱的张三先生/女士,您在途虎购买的货品(单号TH123456)已 到指定安装店多日,现需与您确认订单的安装情况,请点击链接按实际情况选择(此链接有效期为72H)。您也可以登录途 虎APP进入“我的-待安装订单”进行预约安装。若您在服务过程中有任何疑问,请致电400-111-8868向途虎咨 询。",
"state" : 0
}
},
{
"_index" : "sms-logs-index",
"_type" : "_doc",
"_id" : "23",
"_score" : 0.6931472,
"_source" : {
"corpName" : "盒马鲜生",
"createDate" : 1607833539131,
"fee" : 5,
"ipAddr" : "10.126.2.9",
"longCode" : "10660000988",
"mobile" : "13100000000",
"operatorId" : 2,
"province" : "北京",
"replyTotal" : 15,
"sendDate" : 1607833539131,
"smsContent" : "【盒马】您尾号12345678的订单已开始配送,请在您指定的时间收货不要走开 哦~配送员:刘三,电话:13800000000",
"state" : 0
}
}
]
}
}代码实现方式
// Java代码实现方式
@Test
public void termQuery() throws IOException {
//1. 创建Request对象
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0);
builder.size(5);
builder.query(QueryBuilders.termQuery("province","北京"));
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取到_source中的数据,并展示
for (SearchHit hit : resp.getHits().getHits()) {
Map<String, Object> result = hit.getSourceAsMap();
System.out.println(result);
}
}6.1.2 terms查询
terms和term的查询机制是一样,都不会将指定的查询关键字进行分词,直接去分词库中匹配,找到相应文档内容。
terms是在针对一个字段包含多个值的时候使用。
term:where province = 北京;
terms:where province = 北京 or province = ?or province = ? 一个字段可以等于多个值 有点类似 in
# terms查询
POST /sms-logs-index/_search
{
"query": {
"terms": {
"province": [
"北京",
"山西",
"武汉"
]
}
}
}代码实现方式
// Java实现
@Test
public void termsQuery() throws IOException {
//1. 创建request
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 封装查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termsQuery("province","北京","山西"));
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出_source
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.2 match查询【重点】
match查询属于高层查询,他会根据你查询的字段类型不一样,采用不同的查询方式。
- 查询的是日期或者是数值的话,他会将你基于的字符串查询内容转换为日期或者数值对待。
- 如果查询的内容是一个不能被分词的内容(keyword),match查询不会对你指定的查询关键字进行分词。
- 如果查询的内容时一个可以被分词的内容(text),match会将你指定的查询内容根据一定的方式去分词,去分词库中匹配指定的内容。
match查询,实际底层就是多个term查询,将多个term查询的结果给你封装到了一起。
6.2.1 match_all查询
查询全部内容,不指定任何查询条件。
# match_all查询
POST /sms-logs-index/_search
{
"query": {
"match_all": {}
}
}代码实现方式
// java代码实现
@Test
public void matchAllQuery() throws IOException {
//1. 创建Request
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchAllQuery());
builder.size(20); // ES默认只查询10条数据,如果想查询更多,添加size
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
System.out.println(resp.getHits().getHits().length);
}6.2.2 match查询
指定一个Field作为筛选的条件
# match查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": "收货安装" # smsContent 是 text 类型,match 会自动识别 会对查询条件也进行分词 也就是 把收获安装 按照分词器规则 拆分,比如 拆为 收获 和 安装 去和文档进行匹配
}
}
}代码实现方式
@Test
public void matchQuery() throws IOException {
//1. 创建Request
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//-----------------------------------------------
builder.query(QueryBuilders.matchQuery("smsContent","收货安装"));
//-----------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.2.3 布尔match查询
基于一个Field匹配的内容,采用and或者or的方式连接
# 布尔match查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": {
"query": "中国 健康",
"operator": "and" # 内容既包含中国也包含健康
}
}
}
}
# 布尔match查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": {
"query": "中国 健康",
"operator": "or" # 内容包括健康或者包括中国
}
}
}
}代码实现方式
// Java代码实现
@Test
public void booleanMatchQuery() throws IOException {
//1. 创建Request
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------- 选择AND或者OR
builder.query(QueryBuilders.matchQuery("smsContent","中国 健康").operator(Operator.OR));
//-----------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.2.4 multi_match查询
match针对一个field做检索,multi_match针对多个field进行检索,多个field对应一个text。
# multi_match 查询
POST /sms-logs-index/_search
{
"query": {
"multi_match": {
"query": "北京", # 指定text
"fields": ["province","smsContent"] # 指定field们
}
}
}代码实现方式
// java代码实现
@Test
public void multiMatchQuery() throws IOException {
//1. 创建Request
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//-----------------------------------------------
builder.query(QueryBuilders.multiMatchQuery("北京","province","smsContent"));
//-----------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.3 其他查询
6.3.1 id查询
根据id查询 where id = ?
# id查询
GET /sms-logs-index/_doc/1 # GET /sms-logs-index/_doc/1代码实现方式
// Java代码实现
@Test
public void findById() throws IOException {
//1. 创建GetRequest
GetRequest request = new GetRequest(index,"1");
//2. 执行查询
GetResponse resp = client.get(request, RequestOptions.DEFAULT);
//3. 输出结果
System.out.println(resp.getSourceAsMap());
}6.3.2 ids查询
根据多个id查询,类似MySQL中的where id in(id1,id2,id2...)
# ids查询
POST /sms-logs-index/_search
{
"query": {
"ids": {
"values": ["1","2","3"]
}
}
}代码实现方式
// Java代码实现
@Test
public void findByIds() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------------------
builder.query(QueryBuilders.idsQuery().addIds("1","2","3"));
//----------------------------------------------------------
request.source(builder);
//3. 执行
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.3.3 prefix查询
前缀查询,可以通过一个关键字去指定一个Field的前缀,从而查询到指定的文档。
#prefix 查询
POST /sms-logs-index/_search
{
"query": {
"prefix": {
"corpName": {
"value": "途虎"
}
}
}
}代码实现方式
// Java实现前缀查询
@Test
public void findByPrefix() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------------------
builder.query(QueryBuilders.prefixQuery("corpName","盒马"));
//----------------------------------------------------------
request.source(builder);
//3. 执行
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.3.4 fuzzy查询
模糊查询,我们输入字符的大概(比如 出现错别字),ES就可以去根据输入的内容大概去匹配一下结果。
# fuzzy查询
POST /sms-logs-index/_search
{
"query": {
"fuzzy": {
"corpName": {
"value": "盒马先生",
"prefix_length": 2 # 指定前面几个字符是不允许出现错误的
}
}
}
}代码实现方式
// Java代码实现Fuzzy查询
@Test
public void findByFuzzy() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------------------
builder.query(QueryBuilders.fuzzyQuery("corpName","盒马先生").prefixLength(2));
//----------------------------------------------------------
request.source(builder);
//3. 执行
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.3.5 wildcard查询
通配查询,和MySQL中的like是一个套路,可以在查询时,在字符串中指定通配符*和占位符?
*号匹配多个字符 ?匹配一个字符
# wildcard 查询
POST /sms-logs-index/_search
{
"query": {
"wildcard": {
"corpName": {
"value": "中国*" # 可以使用*和?指定通配符和占位符
}
}
}
}代码实现方式
// Java代码实现Wildcard查询
@Test
public void findByWildCard() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------------------
builder.query(QueryBuilders.wildcardQuery("corpName","中国*"));
//----------------------------------------------------------
request.source(builder);
//3. 执行
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.3.6 range查询
范围查询,只针对数值类型,对某一个Field进行大于或者小于的范围指定
# range 查询
POST /sms-logs-index/_search
{
"query": {
"range": {
"fee": {
"gt": 5,
"lte": 10
# 可以使用 gt:> gte:>= lt:< lte:<=
}
}
}
}代码实现方式
// Java实现range范围查询
@Test
public void findByRange() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------------------
builder.query(QueryBuilders.rangeQuery("fee").lte(10).gte(5));
//----------------------------------------------------------
request.source(builder);
//3. 执行
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.3.7 regexp查询
正则查询,通过你编写的正则表达式去匹配内容。
# regexp 查询
POST /sms-logs-index/_search
{
"query": {
"regexp": {
"mobile": "180[0-9]{8}" # 编写正则
}
}
}代码实现方式
// Java代码实现正则查询
@Test
public void findByRegexp() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//----------------------------------------------------------
builder.query(QueryBuilders.regexpQuery("mobile","139[0-9]{8}"));
//----------------------------------------------------------
request.source(builder);
//3. 执行
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.4 深分页Scroll
ES对from + size是有限制的,from和size二者之和不能超过1W
原理:
from+size在ES查询数据的方式:
- 第一步现将用户指定的关键进行分词。
- 第二步将词汇去分词库中进行检索,得到多个文档的id。
- 第三步去各个分片中去拉取指定的全部数据。耗时较长。
- 第四步将数据根据score进行排序。耗时较长。
- 第五步根据from的值,将查询到的数据舍弃一部分。
- 第六步返回结果。
scroll+size在ES查询数据的方式:
- 第一步现将用户指定的关键进行分词。
- 第二步将词汇去分词库中进行检索,得到多个文档的id。
- 第三步将文档的id存放在一个ES的上下文中。
- 第四步根据你指定的size的个数去ES中检索指定个数的数据,拿完数据的文档id,会从上下文中移除。
- 第五步如果需要下一页数据,直接去ES的上下文中,找后续内容。
- 第六步循环第四步和第五步
# 执行scroll查询,返回第一页数据,并且将文档id信息存放在ES上下文中,指定生存时间1m
POST /sms-logs-index/sms-logs-type/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 2,
"sort": [ # 排序 默认是根据id字段排序
{
"fee": { # 自定义排序字段 也可以指定多个字段排序,比如 fee一样时,按照另一个字段排序
"order": "desc"
}
}
]
}
# 根据scroll查询下一页数据
POST /_search/scroll
{
"scroll_id": "<根据上面第一步得到的scorll_id去指定>",
"scroll": "<scorll信息的生存时间>" # 第二次查询 要重新指定上下文存活时间 要不然第二次查询之后 上下文就没了
}
# 当全部查询完之后 这个 scroll_id 对应的es上下文中的doc id 都被移除干净了
# 删除scroll在ES上下文中的数据
DELETE /_search/scroll/scroll_id代码实现方式
// Java实现scroll分页
@Test
public void scrollQuery() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定scroll信息
request.scroll(TimeValue.timeValueMinutes(1L));
//3. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.size(4);
builder.sort("fee", SortOrder.DESC);
builder.query(QueryBuilders.matchAllQuery());
request.source(builder);
//4. 获取返回结果scrollId,source
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
String scrollId = resp.getScrollId();
System.out.println("----------首页---------");
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
while(true) {
//5. 循环 - 创建SearchScrollRequest
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
//6. 指定scrollId的生存时间
scrollRequest.scroll(TimeValue.timeValueMinutes(1L));
//7. 执行查询获取返回结果
SearchResponse scrollResp = client.scroll(scrollRequest, RequestOptions.DEFAULT);
//8. 判断是否查询到了数据,输出
SearchHit[] hits = scrollResp.getHits().getHits();
if(hits != null && hits.length > 0) {
System.out.println("----------下一页---------");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsMap());
}
}else{
//9. 判断没有查询到数据-退出循环
System.out.println("----------结束---------");
break;
}
}
//10. 创建CLearScrollRequest
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
//11. 指定ScrollId
clearScrollRequest.addScrollId(scrollId);
//12. 删除ScrollId
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
//13. 输出结果
System.out.println("删除scroll:" + clearScrollResponse.isSucceeded());
}6.5 delete-by-query
根据term,match等查询方式去删除大量的文档
Ps:如果你需要删除的内容,是index下的大部分数据,推荐创建一个全新的index,将保留的文档内容,添加到全新的索引
# delete-by-query
POST /sms-logs-index/sms-logs-type/_delete_by_query
{
"query": {
"range": {
"fee": {
"lt": 4
}
}
}
}代码实现方式
// Java代码实现
@Test
public void deleteByQuery() throws IOException {
//1. 创建DeleteByQueryRequest
DeleteByQueryRequest request = new DeleteByQueryRequest(index);
//2. 指定检索的条件 和SearchRequest指定Query的方式不一样
request.setQuery(QueryBuilders.rangeQuery("fee").lt(4));
//3. 执行删除
BulkByScrollResponse resp = client.deleteByQuery(request, RequestOptions.DEFAULT);
//4. 输出返回结果
System.out.println(resp.toString());
}6.6 复合查询
6.6.1 bool查询
复合过滤器,将你的多个查询条件,以一定的逻辑组合在一起。
- must: 所有的条件,用must组合在一起,表示And的意思
- must_not:将must_not中的条件,全部都不能匹配,标识Not的意思
- should:所有的条件,用should组合在一起,表示Or的意思
# 查询省份为武汉或者北京
# 运营商不是联通
# smsContent中包含中国和平安
# bool查询
POST /sms-logs-index/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"province": {
"value": "北京"
}
}
},
{
"term": {
"province": {
"value": "武汉"
}
}
}
],
"must_not": [
{
"term": {
"operatorId": {
"value": "2"
}
}
}
],
"must": [
{
"match": {
"smsContent": "中国"
}
},
{
"match": {
"smsContent": "平安"
}
}
]
}
}
}代码实现方式
// Java代码实现Bool查询
@Test
public void BoolQuery() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// # 查询省份为武汉或者北京
boolQuery.should(QueryBuilders.termQuery("province","武汉"));
boolQuery.should(QueryBuilders.termQuery("province","北京"));
// # 运营商不是联通
boolQuery.mustNot(QueryBuilders.termQuery("operatorId",2));
// # smsContent中包含中国和平安
boolQuery.must(QueryBuilders.matchQuery("smsContent","中国"));
boolQuery.must(QueryBuilders.matchQuery("smsContent","平安"));
builder.query(boolQuery);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.6.2 boosting查询
boosting查询可以帮助我们去影响查询后的score。
- positive:只有匹配上positive的查询的内容,才会被放到返回的结果集中。
- negative:如果匹配上和positive并且也匹配上了negative,就可以降低这样的文档score。
- negative_boost:指定系数,必须小于1.0
关于查询时,分数是如何计算的:
- 搜索的关键字在文档中出现的频次越高,分数就越高
- 指定的文档内容越短,分数就越高
- 我们在搜索时,指定的关键字也会被分词,这个被分词的内容,被分词库匹配的个数越多,分数越高
# boosting查询 收货安装
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"smsContent": "收货安装"
}
},
"negative": {
"match": {
"smsContent": "王五"
}
},
"negative_boost": 0.5
}
}
}代码实现方式
// Java实现Boosting查询
@Test
public void BoostingQuery() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
BoostingQueryBuilder boostingQuery = QueryBuilders.boostingQuery(
QueryBuilders.matchQuery("smsContent", "收货安装"),
QueryBuilders.matchQuery("smsContent", "王五")
).negativeBoost(0.5f);
builder.query(boostingQuery);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.7 filter查询
query,根据你的查询条件,去计算文档的匹配度得到一个分数,并且根据分数进行排序,不会做缓存的。
filter,根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存。
# filter查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"corpName": "盒马鲜生"
}
},
{
"range": {
"fee": {
"lte": 4
}
}
}
]
}
}
}代码实现方式
// Java实现filter操作
@Test
public void filter() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.termQuery("corpName","盒马鲜生"));
boolQuery.filter(QueryBuilders.rangeQuery("fee").lte(5));
builder.query(boolQuery);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}6.8 高亮查询【重点】
高亮查询就是你用户输入的关键字,以一定的特殊样式展示给用户,让用户知道为什么这个结果被检索出来。
高亮展示的数据,本身就是文档中的一个Field,单独将Field以highlight的形式返回给你。
ES提供了一个highlight属性,和query同级别的。
- fragment_size:指定高亮数据展示多少个字符回来。默认100个
- pre_tags:指定前缀标签,举个栗子< font color="red" >
- post_tags:指定后缀标签,举个栗子< /font >
- fields:指定哪几个Field以高亮形式返回
| 效果图 |
|---|
 |
RESTful实现
# highlight查询
POST /sms-logs-index/sms-logs-type/_search
{
"query": {
"match": {
"smsContent": "盒马"
}
},
"highlight": {
"fields": {
"smsContent": {}
},
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fragment_size": 10
}
}代码实现方式
// Java实现高亮查询
@Test
public void highLightQuery() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定查询条件(高亮)
SearchSourceBuilder builder = new SearchSourceBuilder();
//2.1 指定查询条件
builder.query(QueryBuilders.matchQuery("smsContent","盒马"));
//2.2 指定高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("smsContent",10)
.preTags("<font color='red'>")
.postTags("</font>");
builder.highlighter(highlightBuilder);
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取高亮数据,输出
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getHighlightFields().get("smsContent"));
}
}6.9 聚合查询【重点】
aggregations :提供了从数据中分组和提取数据的能力,最简单的聚合方法大致等于SQL GROUP BY 和 SQL 聚合函数。在ES中可以执行搜索返回hits(命中结果),并且同时返回聚合结果,把一个响应中所有hits (命中结果)分隔开的能力,这是非常强大且有效的 ,可以执行多个查询和聚合,并且在一次使用中得到各自的返回结果,使用一次简洁和简化的API来避免网络往返。
ES的聚合查询和MySQL的聚合查询类似,ES的聚合查询相比MySQL要强大的多,ES提供的统计数据的方式多种多样。
# ES聚合查询的RESTful语法
POST /index/type/_search
{
"aggs": {
"名字(agg)": { # 名字 自定义 只会影响返回结果的名字
"agg_type": { # es 给咱们提供的聚合类型 咱们直接使用即可
"属性": "值"
}
}
}
}6.9.1 去重计数查询
去重计数,即Cardinality,第一步先将返回的文档中的一个指定的field进行去重,统计一共有多少条
# 去重计数查询 北京 上海 武汉 山西
# 这些记录中 一共出现了几个省份
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"cardinality": {
"field": "province" # 按照 field 进行去重
}
}
}
}代码实现方式
// Java代码实现去重计数查询
@Test
public void cardinality() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(AggregationBuilders.cardinality("agg").field("province"));
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
Cardinality agg = resp.getAggregations().get("agg");
long value = agg.getValue();
System.out.println(value);
}6.9.2 范围统计
统计一定范围内出现的文档个数,比如,针对某一个Field的值在 0~100,100~200,200~300之间文档出现的个数分别是多少。
范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应的统计。
range,date_range,ip_range
数值统计
# 数值方式范围统计
POST /sms-logs-index/_search
{
"aggs": {
"agg": {
"range": {
"field": "fee",
"ranges": [
{
"to": 5 # 没有等于的效果
},
{
"from": 5, # from有包含当前值的意思 有等于的效果
"to": 10
},
{
"from": 10
}
]
}
}
}
}时间范围统计
# 时间方式范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"date_range": {
"field": "createDate",
"format": "yyyy",
"ranges": [
{
"to": 2000
},
{
"from": 2000
}
]
}
}
}
}ip统计方式
# ip方式 范围统计
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"ip_range": {
"field": "ipAddr",
"ranges": [
{
"to": "10.126.2.9"
},
{
"from": "10.126.2.9"
}
]
}
}
}
}代码实现方式
// Java实现数值 范围统计
@Test
public void range() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
//---------------------------------------------
builder.aggregation(AggregationBuilders.range("agg").field("fee")
.addUnboundedTo(5)
.addRange(5,10)
.addUnboundedFrom(10));
//---------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
Range agg = resp.getAggregations().get("agg");
for (Range.Bucket bucket : agg.getBuckets()) {
String key = bucket.getKeyAsString();
Object from = bucket.getFrom();
Object to = bucket.getTo();
long docCount = bucket.getDocCount();
System.out.println(String.format("key:%s,from:%s,to:%s,docCount:%s",key,from,to,docCount));
}
}6.9.3 统计聚合查询
他可以帮你查询指定Field的最大值,最小值,平均值,平方和等
使用:extended_stats
# 统计聚合查询
POST /sms-logs-index/sms-logs-type/_search
{
"aggs": {
"agg": {
"extended_stats": {
"field": "fee"
}
}
}
}代码实现方式
// Java实现统计聚合查询
@Test
public void extendedStats() throws IOException {
//1. 创建SearchRequest
SearchRequest request = new SearchRequest(index);
//2. 指定使用的聚合查询方式
SearchSourceBuilder builder = new SearchSourceBuilder();
//---------------------------------------------
builder.aggregation(AggregationBuilders.extendedStats("agg").field("fee"));
//---------------------------------------------
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 获取返回结果
ExtendedStats agg = resp.getAggregations().get("agg");
double max = agg.getMax();
double min = agg.getMin();
System.out.println("fee的最大值为:" + max + ",最小值为:" + min);
}其他的聚合查询方式查看官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/index.html
6.10 地图经纬度搜索
ES中提供了一个数据类型 geo_point,这个类型就是用来存储经纬度的。
创建一个带geo_point类型的索引,并添加测试数据
# 创建一个索引,指定一个name,locaiton
PUT /map
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"map": {
"properties": {
"name": {
"type": "text"
},
"location": {
"type": "geo_point"
}
}
}
}
}
# 添加测试数据
PUT /map/map/1
{
"name": "天安门",
"location": {
"lon": 116.403981,
"lat": 39.914492
}
}
PUT /map/map/2
{
"name": "海淀公园",
"location": {
"lon": 116.302509,
"lat": 39.991152
}
}
PUT /map/map/3
{
"name": "北京动物园",
"location": {
"lon": 116.343184,
"lat": 39.947468
}
}6.10.1 ES的地图检索方式
| 语法 | 说明 |
|---|---|
| geo_distance | 直线距离检索方式 |
| geo_bounding_box | 以两个点确定一个矩形,获取在矩形内的全部数据 |
| geo_polygon | 以多个点,确定一个多边形,获取多边形内的全部数据 |
6.10.2 基于RESTful实现地图检索
geo_distance
# geo_distance
POST /map/map/_search
{
"query": {
"geo_distance": {
"location": { # 确定一个点
"lon": 116.433733,
"lat": 39.908404
},
"distance": 3000, # 确定半径 默认为 米 ,可以通过 unit 来指定
"distance_type": "arc" # 指定形状为圆形
}
}
}geo_bounding_box
# geo_bounding_box
POST /map/map/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": { # 左上角的坐标点
"lon": 116.326943,
"lat": 39.95499
},
"bottom_right": { # 右下角的坐标点
"lon": 116.433446,
"lat": 39.908737
}
}
}
}
}geo_polygon
# geo_polygon
POST /map/map/_search
{
"query": {
"geo_polygon": {
"location": {
"points": [ # 指定多个点确定一个多边形
{
"lon": 116.298916,
"lat": 39.99878
},
{
"lon": 116.29561,
"lat": 39.972576
},
{
"lon": 116.327661,
"lat": 39.984739
}
]
}
}
}
}6.10.3 Java实现geo_polygon
// 基于Java实现geo_polygon查询
@Test
public void geoPolygon() throws IOException {
//1. SearchRequest
SearchRequest request = new SearchRequest(index);
request.types(type);
//2. 指定检索方式
SearchSourceBuilder builder = new SearchSourceBuilder();
List<GeoPoint> points = new ArrayList<>();
points.add(new GeoPoint(39.99878,116.298916));
points.add(new GeoPoint(39.972576,116.29561));
points.add(new GeoPoint(39.984739,116.327661));
builder.query(QueryBuilders.geoPolygonQuery("location",points));
request.source(builder);
//3. 执行查询
SearchResponse resp = client.search(request, RequestOptions.DEFAULT);
//4. 输出结果
for (SearchHit hit : resp.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}七、 个人学习
es 官网 开源搜索:Elasticsearch、ELK Stack 和 Kibana 的开发者 | Elastic
7.1基本操作
7.1.1 索引一个文档(保存) 相当于保存一条记录 使用 PUT或者POST ,一般 PUT 多用来做修改操作
保存一条记录,保存到那个索引 的 哪个类型下 ,指定用哪个唯一标识 类似 保存一条记录 到哪个数据库下的哪张表下 指定主键id
- PUT book/novel/1 在 book 索引 下 的 novel 类型 下 保存 1 号数据为
shellPUT book/novel/1 { "name":"大奉打更人", "author":"xxx" } 第一次发送这个请求 是 添加操作 ,

第一次之后 发送这个请求 是 修改操作 版本号 会变 版本号 是不断叠加的

- 使用post 保存一条记录 在 book 索引 下 的 novel 类型 下 保存 2 号数据为
POST book/novel/2
{ "name":"西游记", "author":"xxx" }第一次 执行 是添加操作 ,之后 就是修改操作,使用POST 可以不指定 id , 如果不指定id 会自动生成id
总结PUT和POST的区别:
PUT和POST都可以新增和修改
POST 新增,如果不指定id ,会自动生成id. 指定id 第一次是添加操作,之后 是修改操作, 并且 新增版本号
PUT 必须指定id , 由于put 必须指定id , 我们一般用来做修改操作 ,不指定id 会报错。
7.1.2 查询文档 查询一条记录
查询一条记录 查询 哪个索引 哪个类型 下 指定 id 的数据
GET book/novel/1
shell{ "_index" : "book", # 在哪个索引 "_type" : "novel", # 在哪个类型下 "_id" : "1", # id "_version" : 2, # 版本号 "_seq_no" : 1, # 并发控制字段 每次更新更新都会 + 1 , 用来做乐观锁 "_primary_term" : 2, # 分片 集群相关 "found" : true, # 表示 找到了这个数据 "_source" : { # 数据的内容 "name" : "大奉打更人", "author" : "xxx" } } # 使用乐观锁来控制并发修改时 带上参数 ?if_seq_no=6&if_primary_term=2 来进行乐观锁控制 PUT book/novel/1?if_seq_no=6&if_primary_term=2
7.1.3 更新文档
POST book/novel/1/_update # 会检查 原数据 和 本次更新的数据 做对比 如果要更改的数据 和 原数据一致 则 result 为noop 没有 # 操作 , 版本号 序列号 都不变化
{
"doc":{
"name":"大奉打更人4"
}
}POST book/novel/1 # 不会检查 原数据和要更新的数据 是否发生变化 会直接更新版本 和 序列号
{
"name":"大奉打更人5"
}PUT book/novel/1 # 不对比 直接更新 PUT 不能带 _update
{
"name":"大奉打更人6"
}PUT book/novel/1
{
"name":"大奉打更人6",
"publish":"zz" # 也可以在 更新文档的时候 添加属性
}7.1.4 删除文档 或 索引
DELETE book/novel/3 删除 book 索引下 的 novel type 下的 id 为3 的 记录
DELETE book 删除 索引 book 没有提供 直接删除 type 的方法
7.1.5 bulk 批量操作
POST book/_bulk
{"index":{"_id":"5"}}
{"index":{"_id":"2"}}
语法格式:
{action:{metadata}}\n
{request body}\n
{action:{metadata}}\n
{request body} \n
ex:
复杂实例
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"index":{"_index":"website","_type":"blog"}}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"My update blog post"}}
7.2 进阶检索
7.2.1 SearchAPI
ES 支持两种基本方式检索
方式1 通过使用 REST request URI 发送搜索参数 (uri+ 检索参数)
方式2 通过使用 REST request body 来发送他们 (uri + 请求体)
7.2.2检索信息
一切检索 从_search 开始
get bank/_search 检索 bank 下的所有信息 包括 type 和 docs
get bank/_search?q=*&sort=account_number:asc 请求参数方式 检索
相应结果解释:
took 花费的时间
time_out 有没有超时
_shards 集群情况下 每一个分片 为这个检索 做了什么操作
hits: 命中的记录 即查询到的记录
7.2.3 query DSL 基本语法格式
如下 把请求的参数封装成一个json , es 提供了一个可以查询json 风格的DSL domain -specific-language 领域特定语言。该查询语言非常全面
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started-search.html
GET bank/_search
{
"query": { # 查询条件
"match_all": {}
},
"sort": [ # 排序条件
{
"account_number": {
"order": "desc"
}
}
]
}语法:
{
QUERY_NAME:{
ARGUMENT:VALUE, ARGUMENT:VALUE,......}
}
如果是针对某个字段:
{
QUERY_NAME:{
FIELD_NAME:{ ARGUMENT:VALUE, ARGUMENT:VALUE,......}
}
}
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0
, "size": 5,
"sort": [
{
"account_number": {
"order": "desc"
}
}
]
}
# query 定义如何查询
# match_all 查询类型【代表查询】,es 中可以在query 中组合非常多的查询类型完成复杂查询
# 除了query 参数之外 我们也可以传递其他的参数 以改变查询结果, 如 sort 和 size
# from + size 限定 完成分页功能
# sort 排序 多字段排序 会在前序字段相等时 后续字段内部排序 否则以前序为准7.2.4 query dsl 返回部分字段
# 查询指定字段
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0
, "size": 5,
"sort": [
{
"account_number": {
"order": "desc"
}
}
],
"_source": ["account_number","age","balance"]
}7.2.5 match 匹配查询
基本类型(非字符串) 精确匹配
# 基本类型(非字符串) 精确匹配
GET bank/_search
{
"query": {
"match": {
"account_number": "20"
}
}
}
# match 返回 account_num=20 的 doc
# 全文检索 按照评分进行排序 会对检索条件进行分词匹配
# 字符串,多个单词(分词+全文检索)
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
# 最终查询出address 中包含mill 或者 road 或者 mill road 的所有记录,并给出相关性得分7.2.6 match_phrase 短语匹配
将需要匹配的值当成一个整体单词 (不分词) 进行检索
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
# 查出address 中 包含mill road 的所有记录 并给出相关性得分7.2.7 multi_match 多字段匹配
multi_match 多字段匹配 查询多个字段中 包含某个查询条件的 记录
# match_phrase 多字段匹配
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill movico",
"fields": ["city","address"]
}
}
}
# address 或 city 这两个字段 中包含 mill 或 movico 任一个值 都能查出来7.2.8 bool 复合查询
bool 用来做复合查询:复合语句可以合并任何其他查询语句,包括复合语句,了解这一点是很重要的。这就意味着复合语句之间可以互相嵌套,可以表达非常复杂的逻辑
1.must : 必须达到must 列举的所有条件
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "mill"
}},
{
"match": {
"gender": "M"
}
}
],
"must_not": [
{"match": {
"age": "18"
}}
],
"should": [
{"match": {
"lastname": "Wallace"
}}
]
}
}
}
# 查出 address 必须匹配 mill gender 必须匹配M 的 记录must 必须满足的查询条件 must_not 必须不满足的查询条件 should 最好满足的查询条件 满足了 score 就高 ,不满足 也能查出来
如果query 中只有should 且只有一种匹配规则,那么should 的条件就会被作为默认的匹配条件而去改变查询结果。
filter 结果过滤
并不是所有的查询 都需要产生分数 特别是那些仅用于(filtering)过滤的文档,为了不计算分数 es 会自动检查场景,并且优化查询的执行
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "mill"
}}
],
"filter": {
"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}
}
}
}
}
# filter 也是 过滤查询 只不过 不计算相关性得分term 和match 一样 匹配某个属性的值 ,全文检索字段用match ,其他非text 字段匹配用term
GET bank/_search
{
"query": {
"match": {
"age": 28
}
}
}
GET bank/_search
{
"query": {
"term": {
"age": 28
}
}
}
精确字段 非文本字段 建议使用 term 全匹配 , 文本字段 不建议 使用term 建议使用 match实现精确查找的 match_phrase 和 keyword 的区别 是 keyword 是和某个字段完全匹配, match_phrase 是短语匹配 可以是某个字段的一部分
GET bank/_search
{
"query": {
"match": {
"address.keyword": "789 Madison Street"
}
}
}
# 对比 match_phrase
GET bank/_search
{
"query": {
"match_phrase": {
"address": "Madison Street"
}
}
}以上 是 es 的 检索 功能
下面 来看下 es 的 分析功能
7.3 分析功能
aggregations 执行聚合
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL GROUP BY 和 SQL 聚合函数。在ES 中,你有执行搜索返回hits(命中结果),并且同时返回聚合结果,把一个响应中的所有hits (命中结果)分隔开的能力。这是非常强大且有效的,你可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的API来避免网络往返。
7.3.1搜索address 中 包含mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET bank/_search
{
"query": { # 执行检索
"match": { # match 匹配
"address": "mill"
}
},
"aggs": { # 执行聚合
"ageAgg": { # 聚合的名字 方便展示在结果集中
"terms": { # 聚合的类型 查询这个 age 字段的值 有几种 即 年龄分布值
"field": "age", # 聚合分析的字段
"size": 10 # 取几个值
}
},
"ageAvg":{ # 聚合的名字 平均年龄 起名 ageAvg
"avg": { # 计算 平均值
"field": "age"
}
},
"balanceAvg":{ # 聚合的名字 方便展示在结果集中
"avg": { # 聚合的类型
"field": "balance" # 聚合分析的字段
}
}
},
"size": 0 # 不显示搜索的数据
}语法说明:

7.3.2复杂一点的案例1:
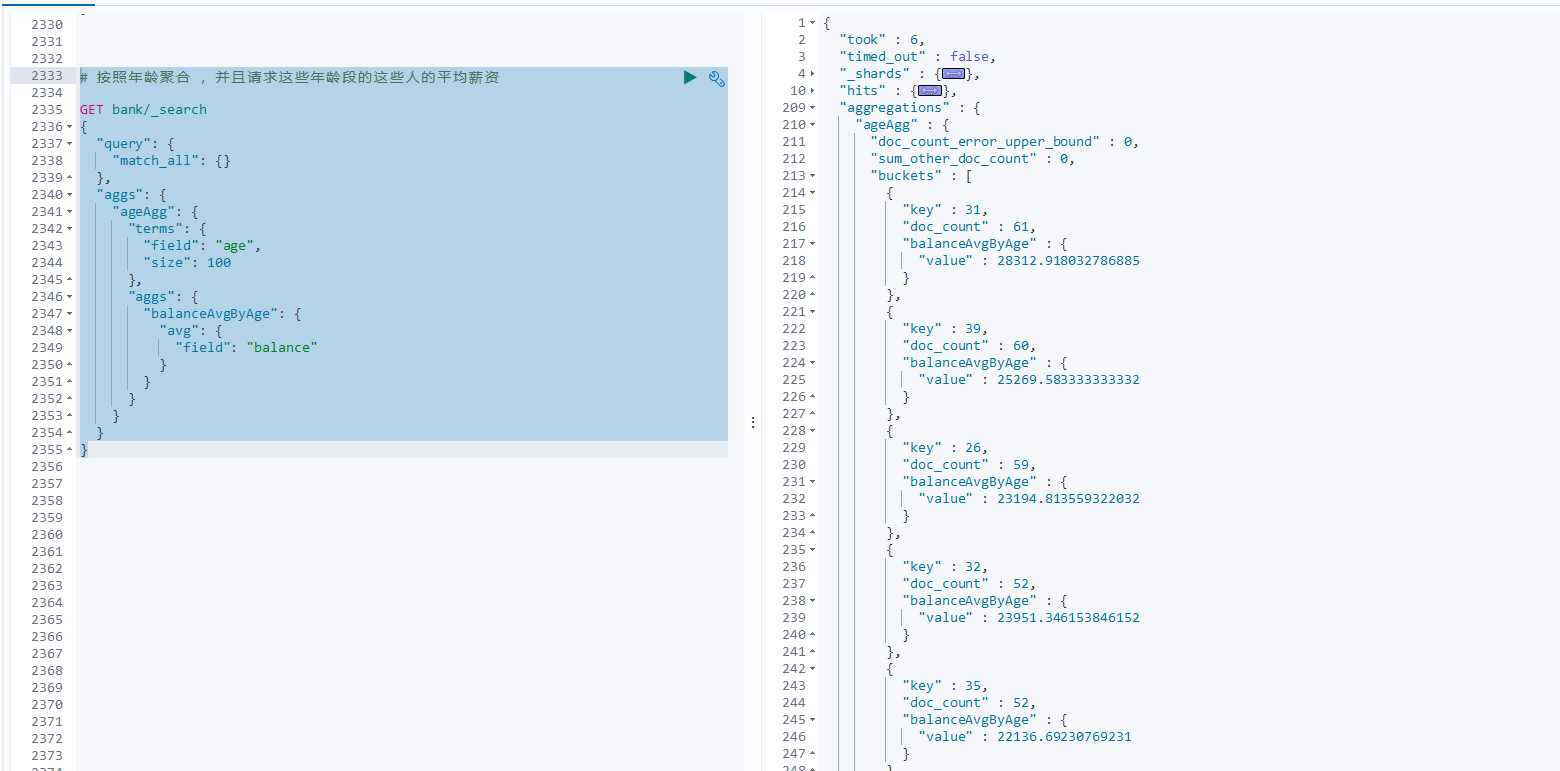
按照年龄聚合 ,并且请求这些年龄段的这些人的平均薪资
# 按照年龄聚合 ,并且请求这些年龄段的这些人的平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"balanceAvgByAge": {
"avg": {
"field": "balance"
}
}
}
}
}
}
7.3.2复杂一点的案例2:
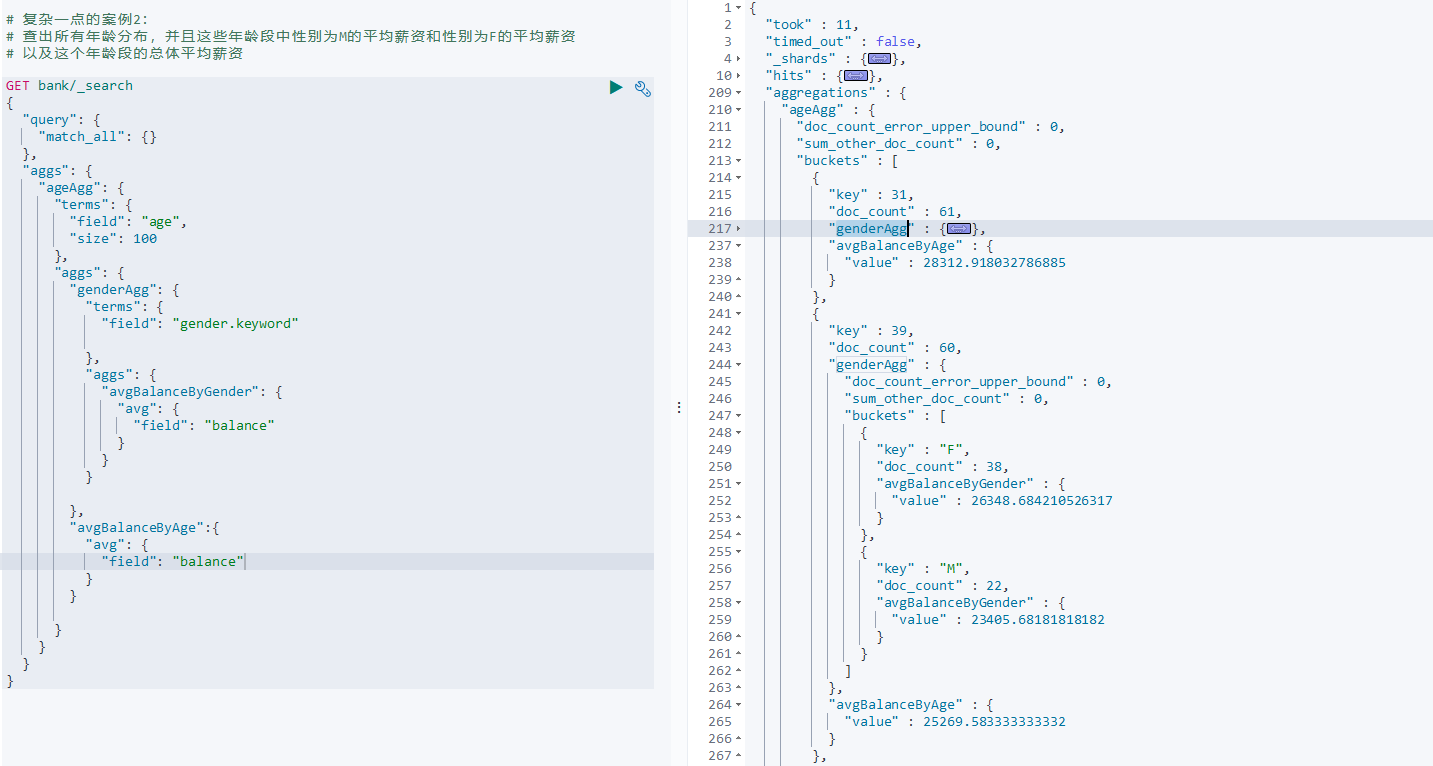
查出所有年龄分布,并且这些年龄段中性别为M的平均薪资和性别为F的平均薪资 以及这个年龄段的总体平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"avgBalanceByGender": {
"avg": {
"field": "balance"
}
}
}
},
"avgBalanceByAge":{
"avg": {
"field": "balance"
}
}
}
}
}
}
7.4 映射 Mapping
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/mapping.html
Mapping 定义一个文档如何来被进行处理的 ,定义属性字段时如何被存储和被检索的,比如 使用 mapping 可以定义哪一个String 类型的字段属性应该被当做全文检索的字段,哪个字段属性 应该包含 数值 或者 日期 或者 地理位置坐标 值, 类似 mysql 创建表时 定义每个属性字段的数据类型。在es 中指的就是映射, ES 中有很多数据类型。es 在第一次保存数据时 会自动猜测数据的类型
查看某个索引的映射情况
get bank/_mapping # ? es7 为什么取出了type 的概念,因为es 底层是lucene ,对不同type 下相同的属性处理方式是一样的,如果有两个不同的type,却有相同的 属性 就必须在不同的type 下定义相同的的field 映射,否则 不同type下的相同field 就会在处理中出现冲突的情况 导致lucene处理效率 下降 去掉type 就是为了提高ES处理数据的效率,ES 8 版本 就不支持 type 了,在es 7 版本只是警告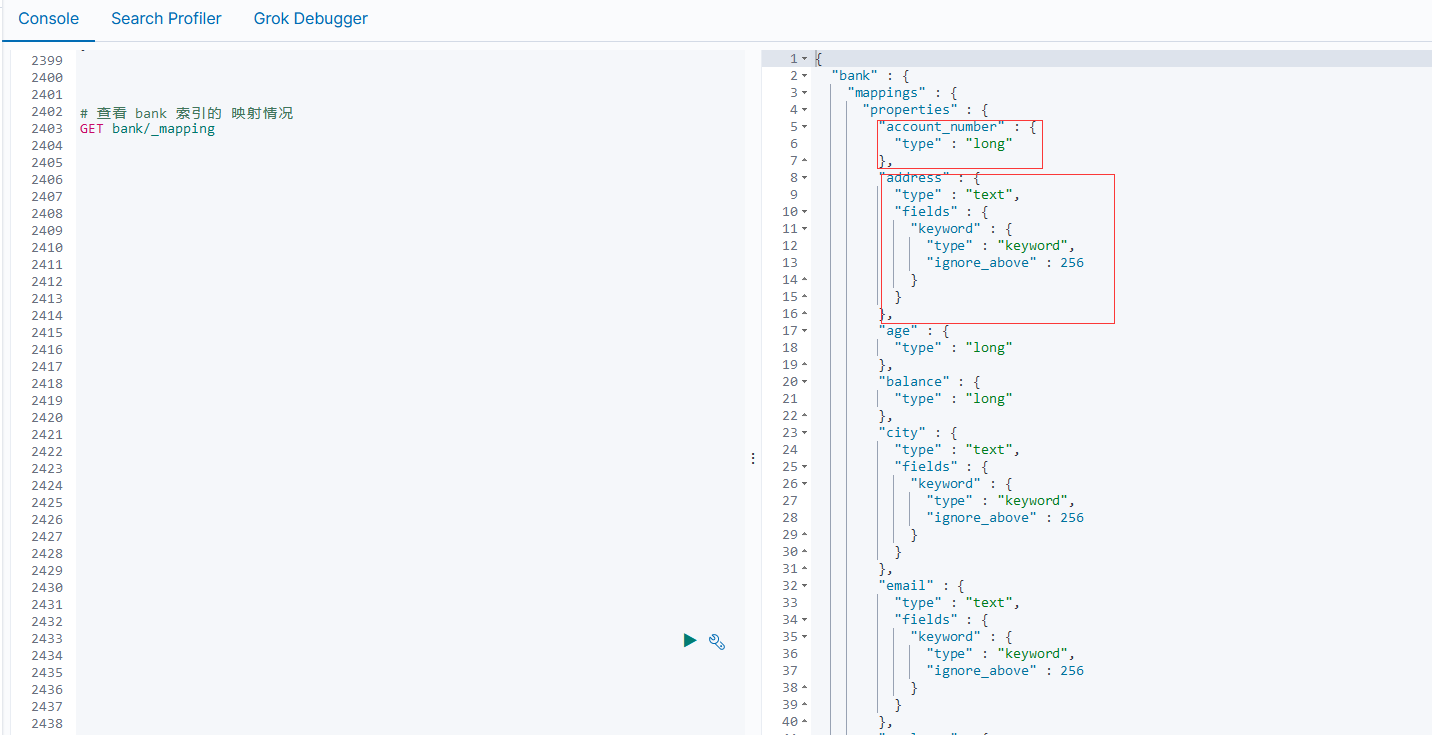
es 默认猜测数据类型映射
JSON type 域type
布尔类型:true或者false boolean
整数: 123 long
浮点数:3.14 double
字符串,有效日期:2020-11-11 date
字符串:hello string
创建索引 并指明映射规则
PUT /my_index # 使用 put 创建索引
{
"mappings": { # mappings 指定映射规则
"properties": {
"age":{"type": "integer"},
"email":{"type":"keyword"}, # keyword 精确匹配
"name":{"type": "text"} # text 全文匹配
}
}
}添加新的字段映射
# 添加新的字段映射
# 字段 参数 index:false 表示当前字段不参与检索 默认为true
PUT /my_index/_mapping
{
"properties":{
"employee-id":{
"type":"keyword",
"index":"false"
}
}
}更新映射 对于已经存在的映射 我们不能更新,因为更改已经存在的映射就会改动之前的检索规则,也就是会牵一发动全身 还不如删除了重建。所以 要 更新映射 , 必须创建新的索引 然后进行数据迁移
# 创建新的索引 属性 要和 旧索引 的属性名字一致
# 创建新的索引
PUT /newbank
{
"mappings": {
"properties": {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "keyword"
},
"email" : {
"type" : "keyword"
},
"employer" : {
"type" : "keyword"
},
"firstname" : {
"type" : "text"
},
"gender" : {
"type" : "keyword"
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "keyword"
}
}
}
}
# 查看创建的新的索引的映射
GET newbank/_mapping
# 把旧的索引中的数据 迁移到新的索引
# 如果旧的索引 有 type 需要指定 type
POST _reindex # 数据迁移
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
# 查看 迁移之后的新的索引中的数据
GET newbank/_search
#数据迁移语法:
POST _reindes
{
"source": {
"index":"oldindex",
"type": "oldtype", # 如果有type 需要指定type
},
"dest": {
"index":"newindex"
}
}7.5ik分词器测试
安装完ik分词器后测试
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
POST _analyze
{
"analyzer": "standard",
"text": "我是中国人"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
# 使用ik分词器 还有个问题 就是一些新词 分词器不能识别 别入一些网络流行语 等 ,所以 咱们可以自定义词库,扩展词库 也比较容易实现,我们可以修改ik分词器的配置文件,让ik 分词器向远程发送请求,要到一些新词,这样 一些新词 就能作为新的词源 进行分解
#实现步骤如下
#修改/usr/share/elasticsearch/plugins/config 中的IKAnalyzer.cfg.xml<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.5.205/fenci/myword.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>定义一个远程请求 让ik 分词器请求这个远程扩展字典 获取最新的分词 我们有两种方式 第一种 自己写个项目 让ik 分词器向这个项目发送请求 处理这个远程请求 返回新的分词 第二种 装上nginx 把最新词库放在nginx 中 让ik 分词器向nginx 发送请求 让nginx 返回最新词库

docker run -p 80:80 --name nginx -d nginx:1.10
docker container cp nginx:/etc/nginx .
docker run -p 80:80 --name nginx -v /mydata/nginx/html:/usr/share/nginx/html -v /mydata/nginx/logs:/var/log/nginx -v /mydata/nginx/conf:/etc/nginx -d nginx:1.10
启动之后 会看到 nginx 文件夹下面 有三个文件夹 conf html logs
在 html 文件夹下 新建 index.html 测试 访问 http://192.168.5.205/ 默认 80 端口 直接能访问到
创建http://192.168.5.205/fenci/myword.txt 继续在这个html 目录下 创建 fenci 文件夹,在这个文件夹内创建 myword.txt ,这个文件中写入新词 glls ,重启 es ,就能看到效果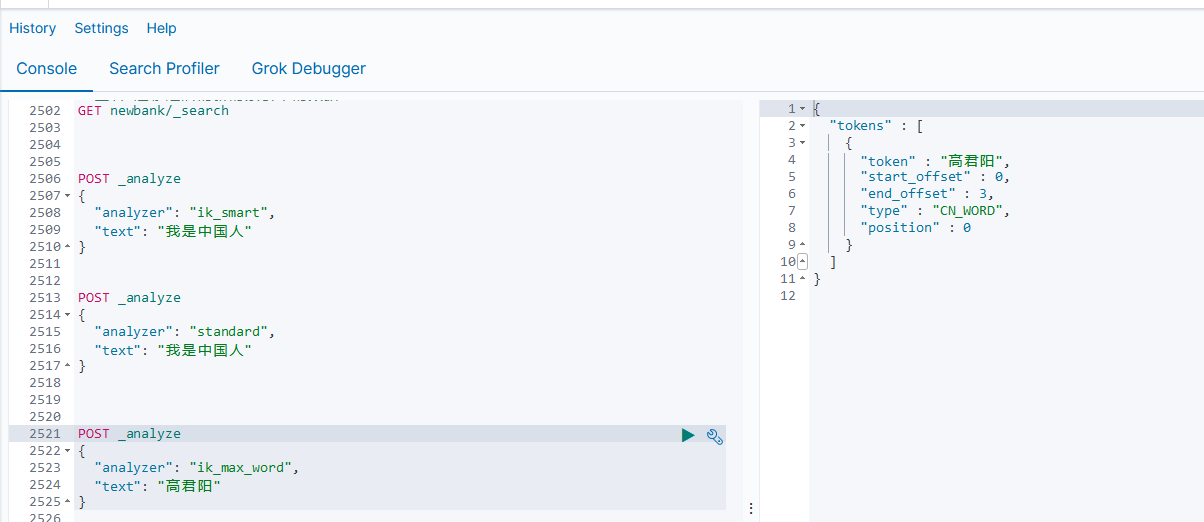
7.6 java 操作es
9300 端口 走TCP 协议 不建议使用 transport-api.jar springboot 与 es 需要适配版本
9200 端口 走 http 协议
解决方案: JestClient 非官方 更新慢
RestTemplate : 模拟发送http 请求 es 很多操作需要自己封装 麻烦 HttpClient 同上 Elasticsearch-Rest-Client : 官方RestClient 封装了ES 操作 ,API 层次分明 上手简单所以 最终选择 Elasticsearch-Rest-Client
为什么不在前端直接发送请求操作es?
- 不对外暴露9200 端口,为了安全
- js 直接发送请求到 es , api 支持度低 ,使用java 很多方法都封装好了 方便
7.6.1springboot 整合elasticsearch
1.添加依赖
shell<dependency> <!--导入 es 的 高阶 api 来 操作 es 要进行配置 如果使用spsringdata 操作es 配置会比较简单 只需要在配置文件指定es 的地址就好了 我们是自己配的 所以自己对es 做配置 --> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version> </dependency> 引入这个依赖后 发现 elasticsearch 的版本是6.8.7 ,这是因为 springboot 对es 的默认支持 如下
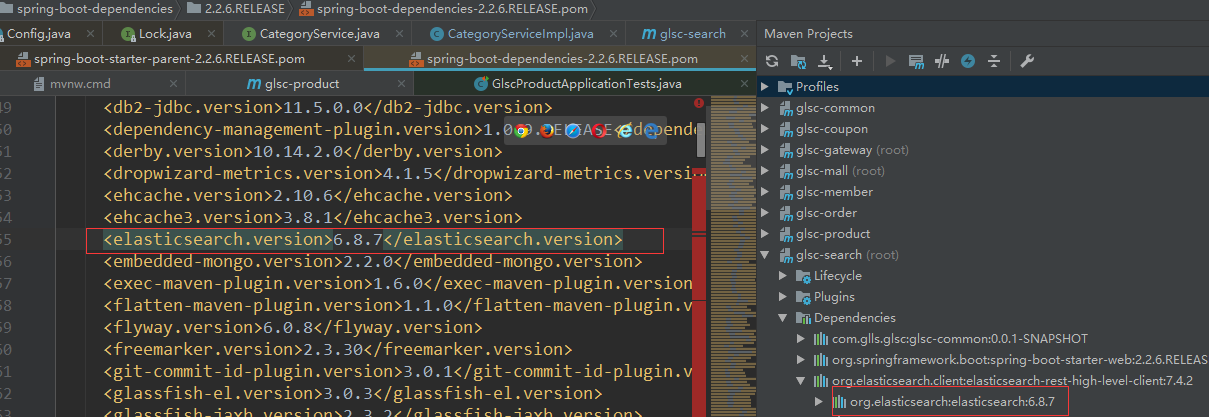
所以 咱们需要手动把这个版本改了 在 搜索模块中 直接指定es 的 版本,把父工程中的版本号覆盖掉

2.编写配置 给容器注入 RestHighLevelClient
# 创建配置类
@Configuration
public class GlscElasticSearchConfig {
//RequestOptions 这个类 主要封装了 访问 ES 的 一些头信息 一些 设置信息
public static final RequestOptions COMMON_OPTIONS;
static {
// 请求设置项
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization","Bearer"+TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30*1024*1024*1024));
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient(){
RestClientBuilder builder = null;
builder = RestClient.builder(new HttpHost("192.168.56.10",9200,"http"));
RestHighLevelClient client = new RestHighLevelClient(builder);
//RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")));
return client;
}
}
# 测试 获取RestHighLevelClient 这个bean
@SpringBootTest
public class GlscSearchApplicationTests {
@Resource
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println(client);
}
}7.6.2 测试保存
/**
* 测试存储数据到es
*
* 如果没内容 就是添加 有内容 就是更新操作
* */
@Test
public void indexData() throws IOException {
// users 是 索引 名字
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("2"); // 数据的id
// 第一种方式
//indexRequest.source("userName","zhangsan","age",18,"gender","男");
// 第二种方式 推荐
User user = new User();
user.setUserName("lisi");
user.setAge(18);
user.setGender("男");
String s = JSON.toJSONString(user);
indexRequest.source(s, XContentType.JSON);
// 网络操作 都会有异常
// 执行保存操作 返回响应
IndexResponse index = client.index(indexRequest, GlscElasticSearchConfig.COMMON_OPTIONS);
//输出响应
System.out.println(index);
}7.6.3 测试检索
参考 https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-search.html
/**
* 测试复杂检索
*
* */
@Test
public void searchData() throws IOException {
//1.创建检索请求
SearchRequest searchRequest = new SearchRequest();
//2. 指定从哪里开始检索 指定索引
searchRequest.indices("bank");
//3.指定 DSL 检索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
//3.1 构造检索条件
// builder.query();
// builder.from();
// builder.size();
// builder.aggregation();
builder.query(QueryBuilders.matchQuery("address","mill"));
// 按照年龄的值分布 进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
builder.aggregation(ageAgg);
// 按照平均薪资 聚合
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
builder.aggregation(balanceAvg);
// 检索条件
System.out.println("检索条件"+builder.toString());
searchRequest.source(builder);
//4. 执行 检索
SearchResponse response = client.search(searchRequest, GlscElasticSearchConfig.COMMON_OPTIONS);
System.out.println(response.toString());
//5. 分析结果 结果封装在 response 对象中
//RestStatus status = response.status(); 得到响应状态码
//TimeValue took = response.getTook(); 花费了多长时间
//boolean timedOut = response.isTimedOut(); 是否超时
// 外层的hits
SearchHits hits = response.getHits(); // 得到所有命中的记录
//TotalHits totalHits = hits.getTotalHits(); // 得到 总记录数
//long value = totalHits.value; // 总记录数
//TotalHits.Relation relation = totalHits.relation; // 相关性得分
//float maxScore = hits.getMaxScore(); //最大得分
// 获取 所有记录 遍历 内层的hits
SearchHit[] searchHits = hits.getHits();
for(SearchHit hit : searchHits){
// String index = hit.getIndex();
// String id = hit.getId();
// float score = hit.getScore();
//
// String sourceAsString = hit.getSourceAsString();
// Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 将返回的数据 转为map
String sourceAsString = hit.getSourceAsString();
Account account = JSON.parseObject(sourceAsString, Account.class);
System.out.println("account:"+account);
}
//获取这次检索到的分析信息
Aggregations aggregations = response.getAggregations();
// List<Aggregation> aggregations1 = aggregations.asList();
// for(Aggregation aggregation : aggregations1){
// System.out.println("当前聚合的名字:"+aggregation.getName());
// }
Terms ageAgg1 = aggregations.get("ageAgg");
for(Terms.Bucket bucket : ageAgg1.getBuckets()){
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄:"+keyAsString);
}
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资:"+balanceAvg1.getValue());
}
@Data
@ToString
static class Account{
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}7.7 elk 环境安装配置
拉取logstash镜像
docker pull logstash:7.4.2# 创建 索引 实际上 这里可以不用创建 直接使用 logstash 添加数据的 时候 创建
PUT /edu_course
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
# 制定索引的数据接口
POST /edu_course/_mapping
{
"properties": {
"description": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"grade": {
"type": "keyword"
},
"id": {
"type": "keyword"
},
"mt": {
"type": "keyword"
},
"name": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"users": {
"index": false,
"type": "text"
},
"charge": {
"type": "keyword"
},
"valid": {
"type": "keyword"
},
"pic": {
"index": false,
"type": "keyword"
},
"qq": {
"index": false,
"type": "keyword"
},
"price": {
"type": "float"
},
"price_old": {
"type": "float"
},
"st": {
"type": "keyword"
},
"status": {
"type": "keyword"
},
"studymodel": {
"type": "keyword"
},
"teachmode": {
"type": "keyword"
},
"teachplan": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"expires": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"pub_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"start_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"end_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}es 和 kibana 都安装好了 ,并保证 ik 分词器好用
准备logstash 的环境
创建文件件
shellcd /opt mkdir docker_logstash mkdir config 把下面的配置文件准备好 放在config 中
mysql.conf
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.133.1:3306/edu_course?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456"
# the path to our downloaded jdbc driver
jdbc_driver_library => "/usr/share/logstash/config/mysql-connector-java-8.0.21.jar" # 这里是连接mysql的jar包
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
statement => "select * from course_pub where timestamp > date_add(:sql_last_value,INTERVAL 8 HOUR)" # 执行的sql命令
#定时配置
schedule => "* * * * *"
record_last_run => true
last_run_metadata_path => "/usr/share/logstash/config/logstash_metadata" # 这里是上次读取时间戳来与数据库查询到的时间戳进行对比,是否向el添加更改数据
}
}
output {
elasticsearch {
#ES的ip地址和端口
hosts => "192.168.133.103:9200"
#hosts => ["localhost:9200","localhost:9202","localhost:9203"]
#ES索引库名称
index => "edu_course"
document_id => "%{id}"
template =>"/usr/share/logstash/config/edu_course_template.json" # 这里是索引的模版文件
template_name =>"edu_course"
template_overwrite =>"true"
}
stdout {
#日志输出
codec => json_lines
}
}edu_course_template.json
{
"mappings" : {
"properties" : {
"charge" : {
"type" : "keyword"
},
"description" : {
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"type" : "text"
},
"end_time" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"expires" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"grade" : {
"type" : "keyword"
},
"id" : {
"type" : "keyword"
},
"mt" : {
"type" : "keyword"
},
"name" : {
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"type" : "text"
},
"pic" : {
"index" : false,
"type" : "keyword"
},
"price" : {
"type" : "float"
},
"price_old" : {
"type" : "float"
},
"pub_time" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"qq" : {
"index" : false,
"type" : "keyword"
},
"st" : {
"type" : "keyword"
},
"start_time" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"type" : "date"
},
"status" : {
"type" : "keyword"
},
"studymodel" : {
"type" : "keyword"
},
"teachmode" : {
"type" : "keyword"
},
"teachplan" : {
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart",
"type" : "text"
},
"users" : {
"index" : false,
"type" : "text"
},
"valid" : {
"type" : "keyword"
}
}
},
"template" : "edu_course"
}docker run -it -p 5044:5044 -p 9600:9600 --name logstash -v /opt/docker_logstash/config:/usr/share/logstash/config --privileged=true logstash:7.4.2 /bin/bashcd /usr/share/logstash/bin
logstash-plugin install logstash-input-jdbc # 安装这个插件 可能会失败几次
把mysql 的 驱动包放在 /usr/share/logstash/logstash-core/lib/jars
如果 连接的是 远程的mysql ,需要开启 mysql 的 远程访问
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
FLUSH PRIVILEGES
要确保 远程连接本地数据库开启,让别人连接你电脑的本地 数据库 ,测试 是否连通 ,可尝试关闭 本地防火墙。
如果 连接不通 启动 logstash 会报 jdbc 连接 异常 这是一个大坑
还有一个大坑 是 启动时 向es 添加数据 时 的 字段解析异常 特别是 带下划线的 中英文敏感 类似 这个字段pub_time 下划线 问题, 手动删除 这个字段的下划线 ,再手动添加上即可解决问题。
给logstash_metadata 授权 ,咱们这里 给整个文件夹授权
chmod -R 777 docker_logstashcd /usr/share/logstash/bin
./logstash -f ../config/mysql.conf # 启动logstash 应用 大概率各种报错 注意查看报错信息注意 loghstash 日志采集 是连续性的 比如 现在停止 logstash , 那么 下次 logstash 的 采集时间 会接着上次采集的时间点 采集,而不是当前时间 , 这样的好处 是logstash 能够采集到 时间点连续的数据
手把手教你 : docker-compose 方式 安装 elk ,采集mysql 数据库的数据到 es 中
参考:(37条消息) docker-compose部署ELK_内涵i的博客-CSDN博客_docker-compose elk
创建目录 : /opt/docker_compose/docker_elk
在这个目录下

创建 docker-compose.yml
version: '3.1'
services:
elasticsearch:
image: daocloud.io/library/elasticsearch:7.4.2 #镜像
container_name: elk_elasticsearch #定义容器名称
restart: always #开机启动,失败也会一直重启
environment:
- "cluster.name=elasticsearch-2201" #设置集群名称为elasticsearch
- "discovery.type=single-node" #以单一节点模式启动
- "ES_JAVA_OPTS=-Xms512m -Xmx1024m" #设置使用jvm内存大小
volumes:
- /opt/docker_compose/docker_elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins #插件文件挂载
- /opt/docker_compose/docker_elk/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载
- /opt/docker_compose/docker_elk/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml #配置文件挂载
ports:
- 9200:9200
- 9300:9300
kibana:
image: daocloud.io/library/kibana:7.4.2
container_name: elk_kibana
restart: always
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200 #设置访问elasticsearch的地址
ports:
- 5601:5601
logstash:
image: logstash:7.4.2
container_name: elk_logstash
restart: always
volumes:
#- /opt/docker_compose/docker_elk/logstash/mysql.conf:/usr/share/logstash/pipeline/logstash.conf #挂载logstash的配置文件
- /opt/docker_compose/docker_elk/logstash/config:/usr/share/logstash/config #挂载logstash的配置文件
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
ports:
- 4560:4560注意: yml 文件中涉及的所有端口 都在防火墙打开
创建elasticsearch目录
在elasticsearch 目录下创建 es 需要挂载的 容器卷

config文件夹下创建 elasticsearch.yml 内容如下
network.host: 0.0.0.0 #使用的网络
http.cors.enabled: true #跨域配置
http.cors.allow-origin: "*"
#xpack.security.enabled: true #开启密码配置注意 chmod -R 777 elasticsearch 授权
创建logstash 目录
在logstash 目录下 创建 logstash 需要挂载的容器卷 config ,config 内 放的是 logstash 的 配置文件

文件介绍:
edu_course_template.json 会依据这个文件 自动在 es 中创建 指定的索引 ,这个索引的结构 需要和 mysql 表的结构对应
mysql.conf logstash 的 核心配置文件 , 配置了 input 指定 数据来自哪里 和 output 指定数据往那里去 ,如果需要改变数据源
就 需要 改动这个文件
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.211.1:3306/edu_course?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456"
# the path to our downloaded jdbc driver
jdbc_driver_library => "/usr/share/logstash/config/mysql-connector-java-8.0.21.jar" # 这里是连接mysql的jar包
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#要执行的sql文件
statement => "select * from course_pub where timestamp > date_add(:sql_last_value,INTERVAL 8 HOUR)" # 执行的sql命令
#定时配置 定时查询上面满足条件的数据 存到es 中
schedule => "* * * * *"
record_last_run => true
last_run_metadata_path => "/usr/share/logstash/config/logstash_metadata" # 这里是上次读取时间戳来与数据库查询到的时间戳进行对比,是否向el添加更改数据
}
}
output {
elasticsearch {
#ES的ip地址和端口
hosts => "192.168.211.102:9200"
#hosts => ["localhost:9200","localhost:9202","localhost:9203"]
#ES索引库名称
index => "edu_course"
document_id => "%{id}"
template =>"/usr/share/logstash/config/edu_course_template.json" # 这里是索引的模版文件
template_name =>"edu_course"
template_overwrite =>"true"
}
stdout {
#日志输出
codec => json_lines
}
}mysql-connector-java-8.0.21.jar mysql 的 驱动 ,这里 需要启动 logstash 容器后 ,进入容器 配置一下
cd /usr/share/logstash/bin
logstash-plugin install logstash-input-jdbc # 安装这个插件 可能会失败几次
把mysql 的 驱动包放在 /usr/share/logstash/logstash-core/lib/jars
如果 连接的是 远程的mysql ,需要开启 mysql 的 远程访问
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
FLUSH PRIVILEGES
要确保 远程连接本地数据库开启,让别人连接你电脑的本地 数据库 ,测试 是否连通 ,可尝试关闭 本地防火墙。
如果 连接不通 启动 logstash 会报 jdbc 连接 异常 这是一个大坑
还有一个大坑 是 启动时 向es 添加数据 时 的 字段解析异常 特别是 带下划线的 中英文敏感 类似 这个字段pub_time 下划线 问题, 手动删除 这个字段的下划线 ,再手动添加上即可解决问题。注意 chmod -R 777 logstash, 这两个目录 递归授权

logstash 配置完之后 ,重启 logstash 容器。
pipelines.yml 这个文件指定了 logstash 启动的时候 读取哪个配置文件
- pipeline.id: main # 注意 格式
path.config: "/usr/share/logstash/config/mysql.conf" # 这个是 启动logstash 读取的配置文件
pipeline.workers: 3采集的数据库 及 表的结构:

创建数据库及表:
DROP TABLE IF EXISTS `course_pub`;
CREATE TABLE `course_pub` (
`id` varchar(32) NOT NULL COMMENT '主键',
`name` varchar(32) NOT NULL COMMENT '课程名称',
`users` varchar(500) NOT NULL COMMENT '适用人群',
`mt` varchar(32) NOT NULL COMMENT '大分类',
`st` varchar(32) NOT NULL COMMENT '小分类',
`grade` varchar(32) NOT NULL COMMENT '课程等级',
`studymodel` varchar(32) NOT NULL COMMENT '学习模式',
`teachmode` varchar(32) DEFAULT NULL COMMENT '教育模式',
`description` text NOT NULL COMMENT '课程介绍',
`timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间戳logstash使用',
`charge` varchar(32) NOT NULL COMMENT '收费规则,对应数据字典',
`valid` varchar(32) NOT NULL COMMENT '有效性,对应数据字典',
`qq` varchar(32) DEFAULT NULL COMMENT '咨询qq',
`price` float(10,2) DEFAULT NULL COMMENT '价格',
`price_old` float(10,2) DEFAULT NULL COMMENT '原价格',
`expires` varchar(32) DEFAULT NULL COMMENT '过期时间',
`start_time` varchar(32) DEFAULT NULL COMMENT '课程有效期-开始时间',
`end_time` varchar(32) DEFAULT NULL COMMENT '课程有效期-结束时间',
`pic` varchar(500) DEFAULT NULL COMMENT '课程图片',
`teachplan` text NOT NULL COMMENT '课程计划',
`pub_time` varchar(32) DEFAULT NULL COMMENT '发布时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `course_pub` */
insert into `course_pub`(`id`,`name`,`users`,`mt`,`st`,`grade`,`studymodel`,`teachmode`,`description`,`timestamp`,`charge`,`valid`,`qq`,`price`,`price_old`,`expires`,`start_time`,`end_time`,`pic`,`teachplan`,`pub_time`) values ('297e7c7c62b8aa9d0162b8accd4c0003','java2201','java基础4','1-3','1-3-2','200002','201001',NULL,'java基础4java基础4java基础4java基础4java基础4java基础4java基础4','2022-06-06 16:18:35','203001','204001',NULL,NULL,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2AJHOeANDrrAAA3Ts5q3pw518.jpg','null','2021-01-27 09:18:34'),('297e7c7c62b8aa9d0162b8ad78a10004','java基础5','java基础5','1-3','1-3-2','200001','201001',NULL,'12345','2021-01-27 08:56:45','203001','204001','123',NULL,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2ANZ1yAQ2YAAACYhkQQGbo003.jpg','{\"children\":[{\"children\":[],\"id\":\"4028058177243f64017724424c820001\",\"pname\":\"java异常机制的引入\"}],\"id\":\"4028058177243f64017724424c820000\",\"pname\":\"java基础5\"}','2021-01-27 08:56:45'),('40280581771504c70177153076670000','vue入门','有一定前端基础','1-1','1-1-9','200003','201002',NULL,'前后端分离 前端工程','2021-09-29 16:10:46','203001','204001',NULL,NULL,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2ANbZ2AJ7r0AACYhkQQGbo338.jpg','null','2021-01-26 16:10:46'),('40280581771856a201771871b0760000','juc并发包','有一定java并发基础的学员','1-3','1-3-2','200003','201001',NULL,'xxxx','2021-01-26 16:18:35','203001','204001','111',NULL,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2AI0WuAK7ZcAACYhkQQGbo409.jpg','{\"children\":[{\"children\":[],\"id\":\"40288ae5771aa2e001771aac6fe50001\",\"pname\":\"1.volitale关键\"}],\"id\":\"40288ae5771aa2e001771aac6fdd0000\",\"pname\":\"juc并发包\"}','2021-01-26 16:16:34'),('40281f81640220d601640222665b0001','java零基础入门','java小白','1-3','1-3-2','200001','201001',NULL,'java零基础入门java零基础入门java零基础入门java零基础入门123','2021-12-17 15:12:38','203001','204001','xxxx',NULL,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2ANbdiAOrt2AACYhkQQGbo098.jpg','null','2021-01-27 08:59:23'),('4028e58161bcf7f40161bcf8b77c0000','spring cloud实战','所有人','1-3','1-3-2','200003','201001',NULL,'本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。','2021-06-10 18:59:01','203002','204002','54354353',0.01,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2ANbjyAcufKAACYhkQQGbo470.jpg','{\"children\":[{\"children\":[{\"id\":\"4028e58161bd18ea0161bd1b00ab0000\",\"pname\":\"为什么要使用微服务:单体架构的特点\"},{\"id\":\"4028e58161bd18ea0161bd1bd2d10001\",\"pname\":\"为什么要使用微服务:微服务的优缺点\"}],\"id\":\"4028e58161bd14c20161bd14f1520000\",\"pname\":\"微服务架构入门\"},{\"children\":[{\"id\":\"4028e58161bd18ea0161bd1d2f3f0005\",\"pname\":\"为什么要选择spring cloud?\"},{\"id\":\"4028e58161bd18ea0161bd1d8f1b0006\",\"pname\":\"为什么springcloud要设计一套新的版本升级规则?\"}],\"id\":\"4028e58161bd18ea0161bd1c83590002\",\"pname\":\"spring cloud 基础入门\"},{\"children\":[{\"id\":\"4028e58161bd18ea0161bd1df0ad0007\",\"pname\":\"为什么越来越多的开发者选择使用spring boot?它解决了什么问题?\"},{\"id\":\"4028e58161bd18ea0161bd1f73190008\",\"pname\":\"spring boot的入门例子\"}],\"id\":\"4028e58161bd18ea0161bd1cc4850003\",\"pname\":\"实战-Spring Boot\"},{\"children\":[{\"id\":\"4028e58161bd18ea0161bd1fd31c0009\",\"pname\":\"微服务架构为什么需要注册中心,它解决了什么问题?\"},{\"id\":\"4028e58161bd18ea0161bd202c45000a\",\"pname\":\" 一个Eureka注册中心的入门例子\"}],\"id\":\"4028e58161bd18ea0161bd1cf3e10004\",\"pname\":\"注册中心Eureka\"},{\"children\":[{\"id\":\"40288ae57705d2ba0177063ef2500001\",\"pname\":\"feign的引入\"},{\"id\":\"40288ae57705d2ba0177063fa3420002\",\"pname\":\"如何配置feign\"},{\"id\":\"40280581771472f0017714745dd10000\",\"pname\":\"feign的相关注解\"}],\"id\":\"40288ae57705d2ba0177063cf5950000\",\"pname\":\"feign\"}],\"id\":\"22\",\"pname\":\"spring cloud与spring boot实战\"}','2021-01-27 08:59:01'),('4028e58161bd3b380161bd3bcd2f0000','Redis从入门到项目实战','','1-3','1-3-2','200002','201001',NULL,'redis在当前的大型网站和500强企业中,已被广泛应用。 redis是基于内存的key-value数据库,比传统的关系型数据库在性能方面有非常大的优势。 肖老师这套视频,精选了redis在实际项目中的十几个应用场景。通过本课程的学习,可以让学员快速掌握redis在实际项目中如何应用。 作为架构师,redis是必须要掌握的技能!','2021-12-17 15:33:48','203002','204001','32432432',0.01,NULL,NULL,NULL,NULL,'group1/M00/00/00/wKiFZ2ANbcGAI9ArAACYhkQQGbo336.jpg','{\"children\":[{\"children\":[{\"grade\":\"3\",\"id\":\"4028e58161bd3b380161bd3fe9220008\",\"mediaFileOriginalName\":\"1.测试NoSql简介.avi\",\"mediaId\":\"320121d2e1cbfc38a56d89abe3569aeb\",\"pname\":\"第一节 NoSQL简介\"},{\"grade\":\"3\",\"id\":\"4028e58161bd3b380161bd40cf340009\",\"mediaFileOriginalName\":\"2.认识Redis.avi\",\"mediaId\":\"734d4a717dc3bae5cefa9315b3be0e7f\",\"pname\":\"第二节 认识Redis\"}],\"grade\":\"2\",\"id\":\"4028e58161bd3b380161bd3e47da0003\",\"pname\":\"第一章:redis简介\"},{\"children\":[],\"grade\":\"2\",\"id\":\"4028e58161bd3b380161bd3f484c0004\",\"pname\":\"第二章:redis的安装与配置\"},{\"children\":[],\"grade\":\"2\",\"id\":\"4028e58161bd3b380161bd3f6f440005\",\"pname\":\"第三章:Redis数据操作\"},{\"children\":[],\"grade\":\"2\",\"id\":\"4028e58161bd3b380161bd3fb0050006\",\"pname\":\"第四章:Redis进阶操作\"},{\"children\":[],\"grade\":\"2\",\"id\":\"4028e58161bd3b380161bd3fd3420007\",\"pname\":\"第五章:Redis主从配置\"}],\"grade\":\"1\",\"id\":\"4028e58161bd3b380161bd3bcd400001\",\"pname\":\"Redis从入门到项目实战\"}','2021-06-09 18:33:48');八、Elasticsearch 环境
8.1概念
8.1.1单机&集群
单台 Elasticsearch 服务器提供服务,往往都有最大的负载能力,超过这个阈值,服务器 性能就会大大降低甚至不可用,所以生产环境中,一般都是运行在指定服务器集群中。
除了负载能力,单点服务器也存在其他问题:
- 单台机器存储容量有限
- 单服务器容易出现单点故障,无法实现高可用
- 单服务的并发处理能力有限
配置服务器集群时,集群中节点数量没有限制,大于等于 2 个节点就可以看做是集群了。一 般出于高性能及高可用方面来考虑集群中节点数量都是 3 个以上。
集群cluster
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供 索引和搜索功能。一个 Elasticsearch 集群有一个唯一的名字标识,这个名字默认就 是”elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入 这个集群。
节点 node
集群中包含很多服务器,一个节点就是其中的一个服务器。作为集群的一部分,它存储 数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色 的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在 这个管理过程中,你会去确定网络中的哪些服务器对应于 Elasticsearch 集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点 都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了 若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做 “elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运 行任何 Elasticsearch 节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的 集群。